


Establishment of a Hyperspectral Spectroscopy-Based Biochemical Component Detection Model for Green Tea Processing Materials
-
摘要: 目的:建立高光谱技术快速检测绿茶加工原料生化成分的方法。方法:用高光谱相机对加工过程中的茶叶原料进行实时拍摄,获取茶叶原料的光谱数据;对样本的含水率、游离氨基酸、茶多酚以及咖啡碱的含量进行检测;光谱数据预处理后,利用无信息变量消除法(uninformative variable elimination,UVE)、竞争性自适应重加权法(competitive adaptive reweighted sampling,CARS)、连续投影算法(successive projections algorithm,SPA)三种特征提取方法与偏最小二乘(partial least-squares,PLS)、支持向量机(support vector machine,SVM)和随机森林(random forest,RF)三种机器学习模型分别组合进行建模分析,预测茶叶原料中的含水率、游离氨基酸、茶多酚和咖啡碱的含量。结果:茶叶原料的含水率、游离氨基酸、茶多酚和咖啡碱最佳组合模型分别为UVE-RF、CARS-SVM、UVE-SVM、UVE-PLS,决定系数(coefficient of determination,R2)分别为0.99、0.92、0.97、0.87,交互验证均方根误差(root mean square error of cross validation,RMSECV)分别为0.7615%、0.723 μg·g−1、0.3701%、0.1197%,相对分析误差(relative percent difference,RPD)分别为10.2093%、25.446 μg·g−1、3.5851%、2.5284%。结论:相关性高,建模误差合理,模型效果优秀,可以有效检测加工过程中茶叶原料的生化成分。该方法不仅无损,而且快速准确,有望在茶叶加工中得到广泛应用。Abstract: Objective: To establish a method for rapid detection of biochemical components of green tea processing materials by hyperspectral technique. Methods: The hyperspectral camera was employed to capture real-time images of the tea raw materials during the processing procedure in order to collect the spectral data of the tea raw materials. The samples' moisture content, free amino acids, tea polyphenols, and caffeine content were all found. After spectral data preprocessing, three feature extraction methods, uninformative variable elimination (UVE), competitive adaptive reweighted sampling (CARS), and successive projections algorithm (SPA) and partial least-squares (PLS), support vector machine (SVM) and random forest (RF) were combined to predict the water content, free amino acids, polyphenols and caffeine content of tea raw materials. Result: The best combination models of water content, free amino acids, tea polyphenols and caffeine of tea raw materials were UVE-RF, CARS-SVM, UVE-SVM and UVE-PLS, with the coefficient of determination (R2) of 0.99, 0.92, 0.97 and 0.87, and the root mean square error of cross validation (RMSECV) of 0.7615%, 0.723 μg·g−1, 0.3701% and 0.1197%, respectively, the relative percent difference (RPD) was 10.2093%, 25.446 μg·g−1, 3.5851% and 2.5284%, respectively. Conclusion: High correlation, appropriate modeling error, outstanding model effect, and the ability to accurately identify the biochemical components of raw materials throughout processing are all characteristics of the model. This technique is not only quick and precise but also non-destructive. In the processing of tea, it is anticipated to be widely employed.
-
在我国,茶叶加工产业想要取得更进一步的发展,高新技术的集成、创新与应用是重中之重。目前,我国的茶叶加工有全手工、半机械以及流水线三种主要方式[1],但三种加工方式都未能做到完全智能化,每一个环节都需要外界人员干预。在加工过程中,都需要采用人工经验与感官评价及时掌握茶叶加工的状况,并且该两种方法都受主观因素影响较大,缺乏可靠的科学根据,并且评判结果容易存在偏差。
高光谱成像技术结合了空间图像数据信息和光谱技术所获得的物质光谱特征,是对物体内部、外部的全面检测技术[2],能利用不同物质的化学键与分子结构差异,检测出茶叶中多酚类、氨基酸类、茶多糖类等多种有效成分的含量和组成[3],相较于传统生化成分检测具有非破坏性、检测速度快的特点,可分析多种生化成分等优势。
近年来,应用光谱技术进行农作物或农产品质量检测的研究已在发展阶段。An等[4]利用高光谱成像技术收集茶叶发酵叶的感官信息,采用不同的数据融合策略结合支持向量机算法SVM建立发酵程度判别模型,预测集准确率达95%以上,模型效果很好。Chen等[5]提取采用主成分分析法后的高光谱图像的纹理特征建立模型,进行茶叶品质分级研究,分级研究效果良好。Curran等[6]利用高光谱研究松针叶片12种生化成分(叶绿素、氮、水、氨基酸等)浓度的高光谱估算模型,证明利用高光谱数据与生化成分研究的可行性;Hong等[7]利用高光谱成像系统对龙井茶的地理来源进行鉴别,建立支持向量机SVM和偏最小二乘判别分析PLS-DA模型,结果较好,校正集与预测集的准确率均超过84%。孙耀国等[8]证明利用近红外光谱技术,可对完整茶叶中的氨基酸、咖啡碱和茶多酚进行定量分析,通过优化波长范围获得较好的PLS模型,但模型选取较为单一。以上研究基本上都是以鲜叶作为研究对象,但对茶叶加工过程中成分检测方面,可研究空间较大。
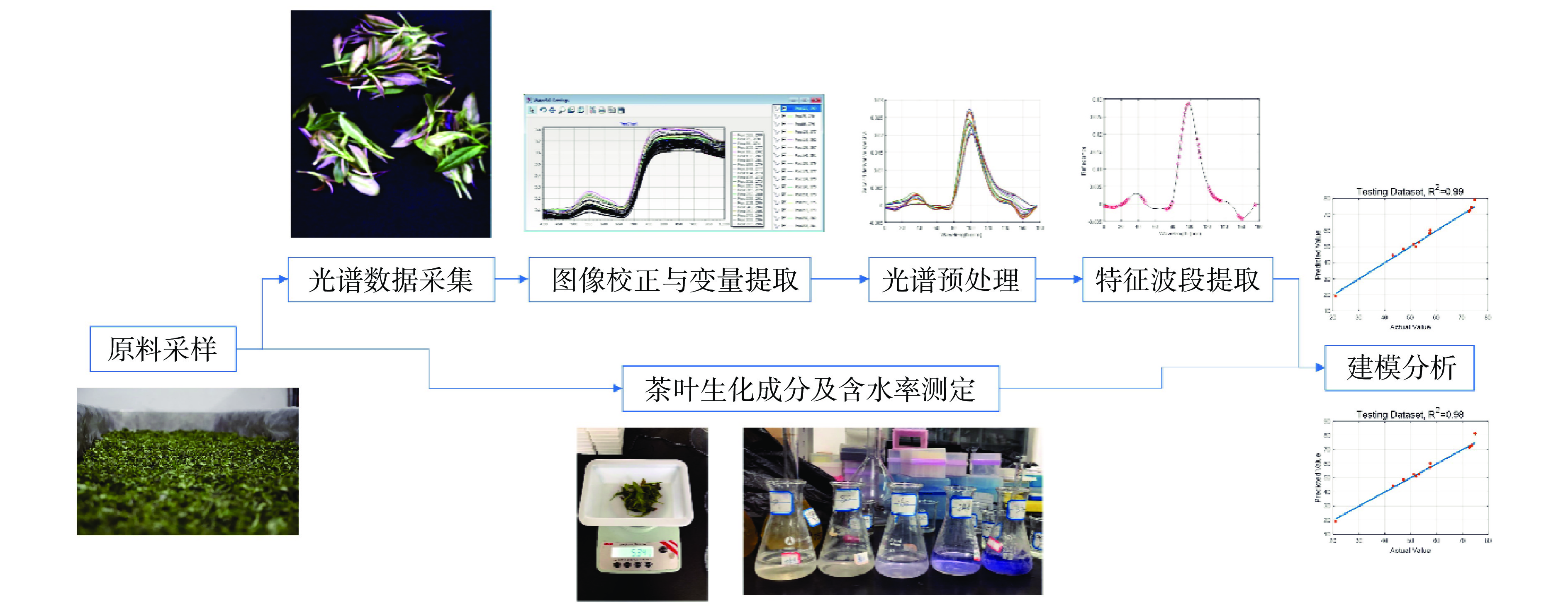
本研究应用高光谱图像技术对同一批加工的茶叶原料进行实时检测,调整原料加工的参数,检测加工原料的含水率与影响茶叶滋味品质的三个主要因素——茶多酚、游离氨基酸(以下简称氨基酸)、咖啡碱[9]。将光谱信息采集与茶叶生化检测相结合,建立光谱技术检测模型。以减少工作量和时间,降低人为主观误差,为茶叶加工的品质检测提供参考,提高生产效率和经济效益。
1. 材料与方法
1.1 材料与仪器
绿茶加工试验 于2021年7月在山东省日照市东港区茶叶科学研究所进行,鲜叶采摘时间为上午8:00~12:00,采摘后当即进行试验。选取茶叶原料品种为鸠坑,原产于浙江省淳安县鸠坑乡,适制绿茶类的龙井、烘青、炒青等,具有抗性强,适应性广等优点。鲜叶采摘标准为一芽一、二叶。茶多酚、氨基酸、咖啡碱含量测定所用的试剂均 为分析纯。
GaiaField Pro-V10便携式地物高光谱成像仪、HSIA-OLE23成像镜头、全漫反射聚四氟乙烯校准白板、HSIA-LSH-200W手持式漫射光源 中国四川双利合浦有限公司;电热鼓风干燥箱 中国上海一恒科学仪器有限公司;高效液相色谱仪 中国上海亚研电子科技有限公司。
1.2 实验方法
1.2.1 原料采样流程
在本试验中,为了获得最佳工艺参数,从而设置不同的加工梯度,并采纳制茶师傅的人工经验下的最佳加工参数,使得试验的采样流程更规范(图1)。在整个采样流程中,每个加工步骤结束后均等待茶叶冷却至常温,进行光谱拍摄与取样,取样每次均三次重复。含水率测量至烘干之前的16个步骤,烘干步骤不进行含水率测量。采样流程如图2所示,鲜叶采摘后,放置于摊晾架中并当即进行取样,保持摊晾位置不变,从而控制摊晾的温度与湿度相对一定,而后每过半小时翻动一次茶叶使其摊晾均匀,每隔1 h取样一次,在最佳摊晾时间4 h后进行下一步杀青;在杀青过程中,以每20 ℃为一个间隔,从180~280 ℃ 中选取6个温度梯度,控制滚筒转速与投叶量一定,在每个温度杀青结束后,留最佳杀青温度260 ℃为大样进行下一步揉捻;在揉捻过程中,设置三个揉捻时间(20、40、60 min)并控制三次投叶量均为2 kg,留最佳揉捻时间40 min进行下一步做形;在做形过程中,使用炒锅与滚筒两种做形方法,均以最佳参数进行处理;在干燥过程中,设置4个温度梯度,干燥时间为40 min,控制摊叶厚度为1 cm与干燥风速恒定,将原料均匀放置于烘干机之上,每隔10 min翻动一次使其受热均匀,以90 ℃为最佳烘干温度,100 ℃为过高温度。样品采集完毕后,放入冰箱−4 ℃避光保存。
1.2.2 光谱数据采集
采用便携式推扫型地物高光谱光谱仪测定原料的光谱反射率,光谱有效范围为400~1000 nm。测量时使用三脚架将光谱仪固定,将相机镜头伸入摄影棚之内,减小外界光源对采集的影响。如图3所示,拍摄时将样品放置于黑布上,将卤素灯放置于摄影棚四角,调整角度使光源聚集于样品。研究采用黑白校正法采集,保证标准白板的反射率为1,扫描白色校正板得到标定图像W,拧上摄像机镜头获取标定图像D (反射率为0的背景),并参考如下黑白校正公式进行图像转换。
C=65552×(R−D)(W−D) (1) 其中C为校正之后的图像,R为图像,D和W分别为反射率为0和1的图像,灰度图像级数为65552,DN范围值为0~65552。
1.2.3 茶叶生化成分及含水量测定
根据《GB/T 8304-2002 茶 水分测定》《GB/T 8313-2002茶 茶多酚测定》《GB/T 8312-2002茶 咖啡碱测定》《GB/T 8314-2013 茶 游离氨基酸总量的测定》,对取到的每个样本的每个生化成分均进行三次测量,检测茶叶样品中含水率、茶多酚总量、游离氨基酸总量和咖啡碱含量。
1.3 光谱图像校正与变量提取
光谱照片采集后,在高光谱图像处理软件Spec-view中,通过镜头与反射率方法校正高光谱图像,得到标准化高光谱图像。在遥感图像处理软件Envi5.3中,使用阈值分割法去除校正后的高光谱图像的背景像素,并通过二值化和掩膜法组合提取样品的平均光谱值。
1.4 光谱预处理
对光谱数据处理后,将所得的样本和样本对应的反射率和生化成分编入同一个EXCEL表格中,以.xlsx的格式保存,在数学软件MATLAB中绘图,得到20种加工步骤的原始光谱曲线,而后对光谱曲线进行预处理。主要为了去除因样品厚度而产生的光散射,提高光谱数据的信噪比以及提供更清晰的光谱轮廓变化。本文采用光谱预处理中常用的三种方法多元散射校正(Multiplicative Scatter Correction,MSC)[10]、S-G平滑(Savitzky-Golay smoothing,简称S-G)[11]与二阶导数法(Second Derivative Algorithm)[12]进行组合,从而更好地提升模型精度[13]。
1.4.1 多元散射校正
多元散射校正(MSC)是高光谱预处理中常用的方法。该方法以建立待测样品的“理想光谱”为标准,对于其余光谱进行基线平移与偏移校正,用于消除样品表面由于光散射而产生的误差,从而增强光谱与数据之间的相关性[14]。
1.4.2 S-G滤波平滑
S-G滤波平滑(简称S-G)利用多项式进行数据平滑,基于最小二乘法,通过对单点数据周围一定大小窗口范围(窗口宽度一般为奇数)内的数据点进行拟合或者平均,分析信号中的有用信息,从而估算出该光谱数据点的理想光谱,达到减小光谱数据中无规律波动的噪声信号对该数据点的干扰以及提高光谱数据信噪比的目的。
1.4.3 二阶导数法
在光谱采集过程中由于受到样品不同组分、实验环境等干扰,导致了光谱基线的漂移(信号位置发生变化)和谱线重叠的现象。使用二阶导数法处理,可以实现光谱数据的基线校正以及消除线性背景平移造成的影响,从而提供更清晰的光谱轮廓变化,提高高光谱数据的分辨率。
1.5 特征波段提取
因高光谱图像数据量特别大且采集时容易受外界环境影响,从而存在很多无用的冗余数据。若将全波段信息都用于建模,则反演模型的计算过程过于繁琐,甚至有会影响模型的鲁棒性与预测精度。因此,为了简化模型并提高模型的稳定性,有必要对预处理后的光谱图像进行无用变量的消除以及关键变量的筛选[15-17]。本文采用三种常用的光谱提取方法分别对预处理后的光谱进行特征筛选,这三种方法分别为无信息变量消除法UVE (uninformative variable elimination)[18]、竞争自适应重加权法CARS (Competitive Adaptive Reweighted Sampling)[19]与连续投影算法SPA (Successive Projections Algorithm)[20]。
1.6 建模方法
为了更全面地反映光谱数据与生化成分的关系以及寻求更精确的结果,使用UVE、CARS、SPA提取的特征向量作为偏最小二乘 (partial least-squares, PLS)[21]、支持向量机 (support vector machine, SVM)[22]、随机森林 (random forest, RF)[23]三种机器学习模型的输入变量,与划分好训练集与预测集的生化成分数据分别建立不同生化成分的算法模型。通过评价模型参数比较各个模型的预测效果,从而选择每个成分最佳预测模型。
1.7 模型评价指标
在本试验中,对所建模型性能使用决定系数R2、校正集相关系数Rcal、预测集相关系数Rp、训练集均方根误差RMSEC、预测集均方根误差RMSEP、交互验证均方根误差RMSECV以及相对分析误差RPD等参数进行评价。
R2、Rcal与Rp三者数值越接近于1,表示相关性越高;RMSEC、RMSEP与RMSECV三者数值不超过2即为合理,否则代表误差较大[24];同种成分建模对比中R2越大,RMSECV越小,则代表建模效果与预测性能越好[25];当RPD≥2.0时,模型可靠性高,具有极好的预测能力;当1.4≤RPD<2.0时,表明该模型可对样本做粗略估测,模型有待改进;当RPD<1.4时,表示模型不可靠[26]。
2. 结果与分析
2.1 加工流程生化成分变化机理分析
本文测量的茶叶含水率、茶多酚、氨基酸、咖啡碱平均值数据分布如表1所示。由表1可知,在摊晾过程中,叶片自然失水含水率下降8%左右;茶多酚含量呈现先增加后减小的趋势,原因可能为摊晾过程中酶活性加强,多酚类物质氧化;氨基酸变化为先增加后减小的规律,最高峰值为摊晾2 h左右,原因可能为鲜叶中绝大多数酶活性增强,从而水解加强,因此蛋白质降解生成氨基酸,但是随着摊晾时间的增长,使得氨基酸氧化还原反应增强,所以导致3 h以后的氨基酸总量呈下降趋势[27];咖啡碱含量呈先增加后减小的趋势,原因可能是摊晾时间增加,导致酶活性增强,鲜叶中的RNA降解生成黄嘌呤核苷酸,黄嘌呤核苷酸再转化为咖啡碱[28]。
表 1 各加工步骤的样品数据平均值Table 1. Average value of sample data for each processing step加工步骤 含水率(%) 茶多酚(%) 氨基酸(×10 μg·g−1) 咖啡碱(%) 茶鲜叶 79.28 23.16 1.86 3.45 摊晾1 h 73.17 24.85 2.12 3.97 摊晾2 h 72.34 26.06 2.49 4.21 摊晾3 h 73.19 24.17 2.16 4.21 摊晾4 h 71.83 22.18 2.19 3.80 杀青180 ℃ 59.23 25.58 1.22 3.55 杀青200 ℃ 57.38 26.80 1.50 4.07 杀青220 ℃ 53.31 24.54 1.39 3.53 杀青240 ℃ 52.78 24.56 1.47 3.49 杀青260 ℃ 48.12 24.24 1.81 3.69 杀青280 ℃ 44.16 25.34 2.00 3.70 揉捻20 min 51.01 22.39 2.45 3.75 揉捻40 min 50.77 21.66 2.33 3.40 揉捻60 min 51.63 22.24 2.50 3.59 滚筒做形 20.40 19.47 2.03 4.26 炒锅做形 15.45 25.15 2.19 3.24 干燥70 ℃ 23.14 2.08 3.57 干燥80 ℃ 21.81 2.08 3.62 干燥90 ℃ 22.88 2.14 3.54 干燥100 ℃ 22.53 2.12 3.38 在杀青过程中,含水率随着温度的升高呈现逐级递减的趋势,变化幅度为15%左右;茶多酚含量呈先上升后减小再小幅度上升的趋势。原因可能为儿茶素高温发生热裂反应,生成一定量无色物质,例如没食子酸,苯甲酸和CO2等[29];氨基酸呈逐渐升高的趋势,原因为蛋白质热水解作用;咖啡碱先增加后趋于平缓的趋势,于桶温为200 ℃最高。
在揉捻过程中,由于主要发生物理反应,四种指标的最高值与最低值之差分别为含水率0.86%、茶多酚0.73%、氨基酸1.7 μg·g−1、咖啡碱0.35%,表明揉捻时间对于茶叶的4项生化成分变化影响并不明显,这也与夏小欢等[30]的结果一致。
在干燥过程中,由数值可知,三种指标的最高值与最低值之差分别为茶多酚1.33%、氨基酸0.6 μg·g−1、咖啡碱0.24%,说明干燥温度在70~100℃之间对于茶叶三种生化成分总量影响不大,这也与宛晓春[31]的结论一致。
2.2 光谱分析
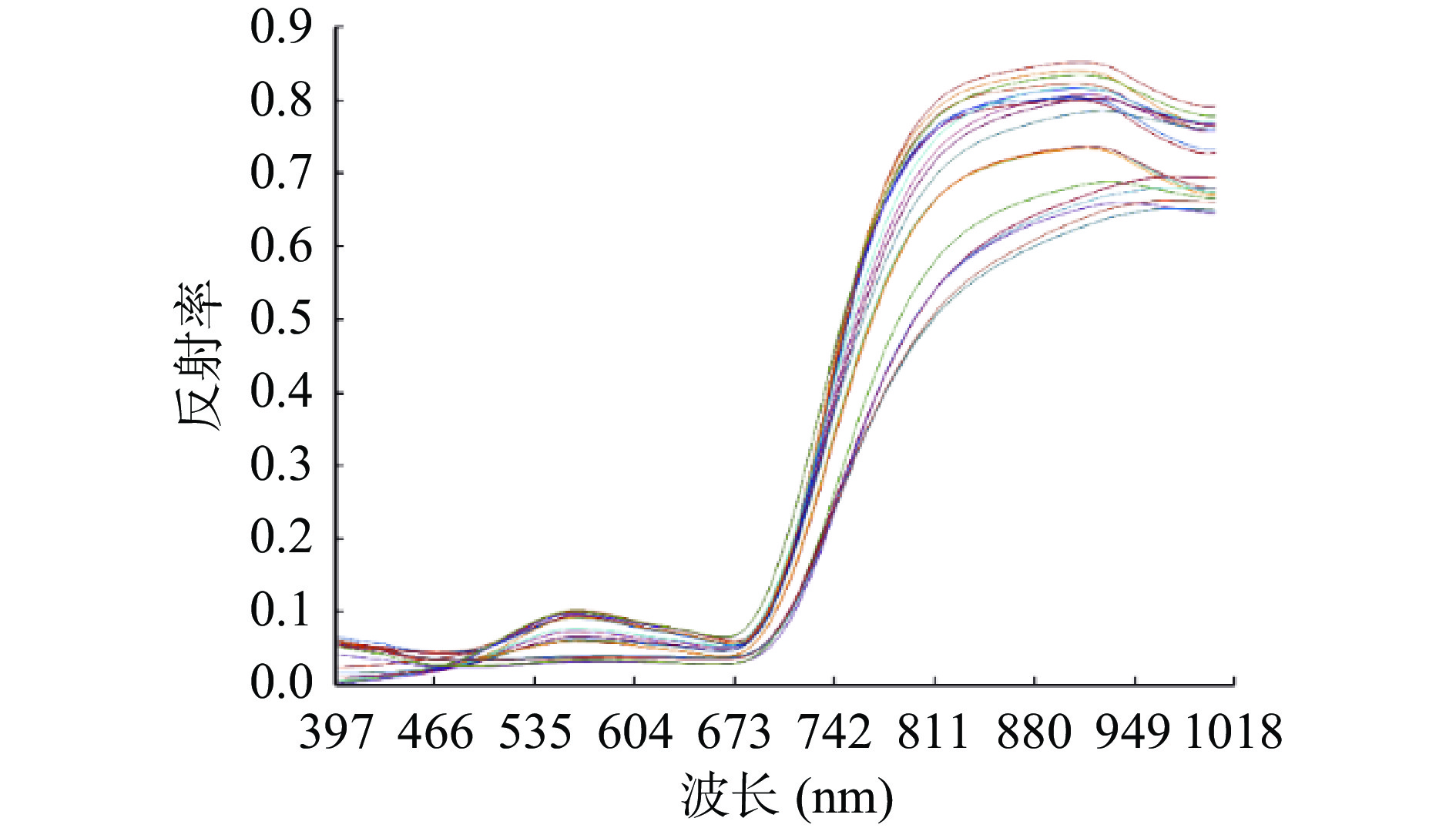
由图4可知,在加工过程中,550 nm附近的绿光区域比较杂乱,并且该区域为叶绿素的强反射区,主要原因为加工过程中大都为加热步骤导致叶绿素发生破坏,从而导致光谱重叠率差;在780 nm以后的近红外区域,谱线非常分散,表明生化成分变化比较大[32]。从高光谱曲线可知,不同加工步骤之间的曲线存在差异,反射率有明显的不同,证明利用高光谱技术研究茶叶原料的加工方面可研究空间较大。
2.3 样本划分与光谱预处理
本文根据总样本数按照3:1的比例选择训练集与预测集,采用多组数据对应同一张光谱图像进行建模。如表2所示,含水率训练集为36个,预测集为12个;茶多酚、氨基酸训练集为43个,预测集为17个;咖啡碱训练集为50个,预测集为15个。表2同时显示了样本的最大值、最小值、均值以及标准差。
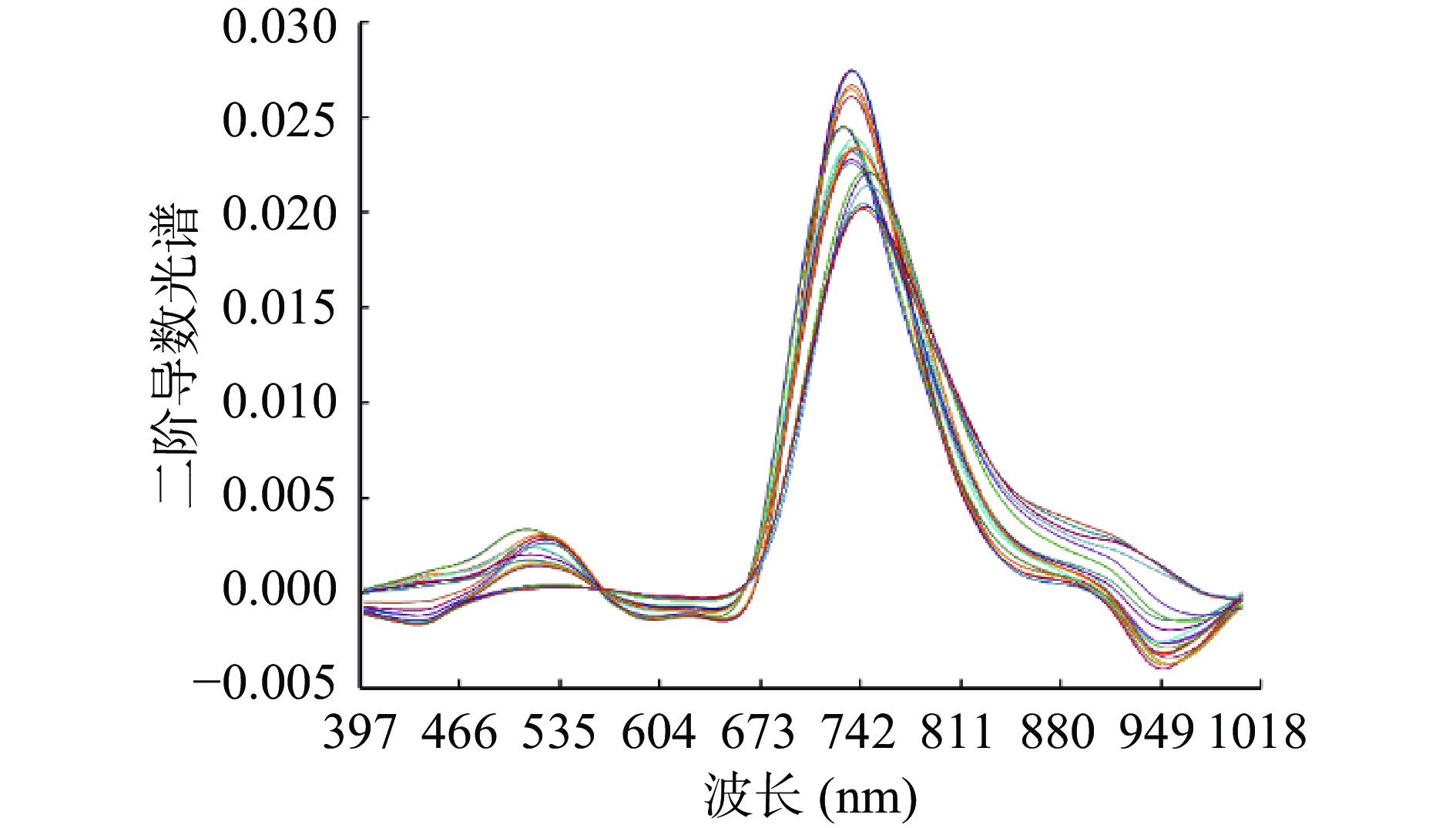
表 2 训练集与测试集的生化成分统计分析Table 2. Statistical Analysis of biochemical components of training set and test set生化成分 光谱图片数量(张) 总样本(个) 训练样本(个) 预测样本(%) 最大值 最小值 均值 标准差 含水率 16 48 36 12 83.72 15 54.64 17.45 茶多酚 20 60 43 17 26.97 18.86 23.64 1.8 氨基酸 20 60 43 17 2.54 0.83 2.01 0.37 咖啡碱 20 65 50 15 5.01 2.84 3.7 0.34 注:咖啡碱测量时,为保障数据准确性,故多测量5组数据,一并用于建模。 由图5分析可知,通过预处理,提高了清晰度,使谱线的峰谷明显,避免重叠峰的干扰。在535 nm附近光谱变化较为明显,742 nm左右为红光反射区域,949 nm的近红外区域波段变化比较大,说明茶叶在加工中生化成分变化非常明显。总体来看,每个加工流程后测得的光谱形状相似,但在反射率上有所不同,这表示茶叶在加工过程中内部成分基本相同,只是在含量上存在差异,为建立生化成分预测模型提供了客观基础。
![]() 图 5 经MSC+二阶导数微分法+S-G平滑处理后的光谱曲线Figure 5. Spectral curve after MSC+second derivative differentiation+S-G smoothing
图 5 经MSC+二阶导数微分法+S-G平滑处理后的光谱曲线Figure 5. Spectral curve after MSC+second derivative differentiation+S-G smoothing2.4 特征波段提取分析
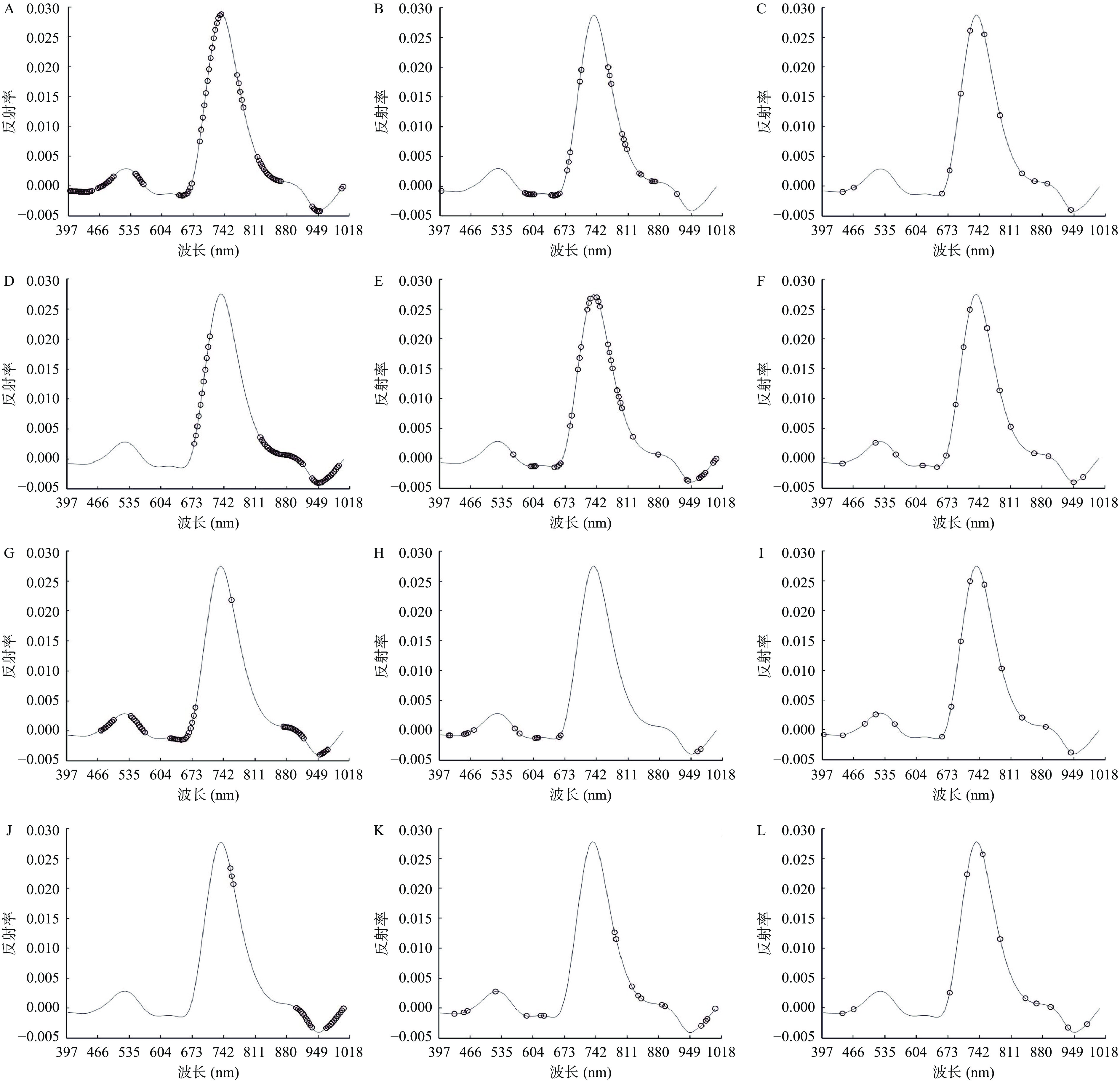
为了提高模型的精度,减小噪声和无关波段的影响,本文通过变量提取从原始光谱数据中筛选了176条波段的光谱数据,并通过三种算法继续筛选出利于建模的变量。由表3可知,在含水率相关的特征波段选择方法中,UVE筛选的特征数目最多,为84个,SPA筛选的特征数目最少,为14个;在茶多酚相关的特征波段选择方法中,UVE筛选的特征数目最多,为55个,SPA筛选的特征数目最少,为16个;在咖啡碱相关的特征波段选择方法中,UVE筛选的特征数目最多,为28个,SPA筛选的特征数目最少,为11个;在氨基酸相关的特征波段选择方法中,UVE筛选的特征数目最多,为48个,SPA筛选的特征数目最少,为14个。图6显示通过光谱与生化数据结合筛选后的特征波段于光谱曲线上的分布,表3为特征波段的数值(精确至个位数)。
表 3 波段筛选结果Table 3. Band screening results生化成分 筛选方法 波长数目 波长范围 含水率 UVE 84 400~449,463~494,545~563,642~670,687~735,770~783,814~866,935~953,1001~1004 CARS 32 401,583~604,642~659,677~683,704~708,766~773,797~808,835~839,863~870,918 SPA 14 442,466,511,556,608,677,701,721,787,839,863,890,935,987 茶多酚 UVE 55 680~708,821~915,935~994 CARS 40 559,597~608,649~663,683~689,701~708,721~749,766~777,787~797,821~877,939~942,966~980,997~1004 SPA 16 404,494,532,639,690,711,725,746,770,801,856,873,894,921,949,973 咖啡碱 UVE 28 507,511,756~763,901~936,966~1004 CARS 18 432,452,459,521,590,621,628,783,787,821,835,842,887,894,973,984,987,1004 SPA 11 442,466,677,714,750,787,842,866,897,935,977 氨基酸 UVE 48 476~497,542~566,649~680,877~918,953~970 CARS 15 418~421,452~459,473,563,573,608~614,659~663,963,970 SPA 14 401,442,490,514,556,659,680,701,721,752,790,835,887,942 ![]() 图 6 特征波段分布注:A-含水率UVE;B-含水率CARS;C-含水率SPA;D-茶多酚UVE;E-茶多酚CARS;F-茶多酚SPA;G-氨基酸UVE;H-氨基酸CARS;I-氨基酸SPA;J-咖啡碱UVE;K-咖啡碱CARS;L-咖啡碱SPA。Figure 6. Characteristic band distribution
图 6 特征波段分布注:A-含水率UVE;B-含水率CARS;C-含水率SPA;D-茶多酚UVE;E-茶多酚CARS;F-茶多酚SPA;G-氨基酸UVE;H-氨基酸CARS;I-氨基酸SPA;J-咖啡碱UVE;K-咖啡碱CARS;L-咖啡碱SPA。Figure 6. Characteristic band distribution2.5 建模分析
本文建模的四种生化成分中包含三种特征提取方法与三种建模方法,总计36组模型数据。本文筛选各成分建模中每三种机器学习模型的最佳结果进行汇总,共计12组,如表4所示。
表 4 模型结果汇总表Table 4. Summary of model results生化成分 模型 训练集 交互验证均方根误差 RMSECV 预测集 均方根误差 RMSEC 相关系数 Rcal 均方根误差 RMSEP 相对分析误差 RPD 相关系数 Rp 决定系数 R2 含水率 UVE-PLS 0.0155 0.9983 0.5483 2.2716 7.3261 0.9914 0.98 CARS-SVM 2.0253 0.9941 1.0458 1.3819 11.4795 0.9959 0.99 UVE-RF 1.5934 0.9936 0.7615 1.4747 10.2093 0.9902 0.99 茶多酚 SPA-PLS 0.0929 0.9031 0.4427 0.6184 2.9274 0.9524 0.91 UVE-SVM 0.6206 0.9356 0.3701 0.5049 3.5851 0.9694 0.97 UVE-RF 0.6033 0.892 0.3598 0.7321 2.226 0.8814 0.88 氨基酸 CARS-PLS 0.0747 0.9405 0.0764 0.1382 2.6253 0.9264 0.86 CARS-SVM 0.1212 0.9478 0.0723 0.1347 2.5446 0.9247 0.92 SPA-RF 0.1148 0.9102 0.0684 0.1399 2.4942 0.8595 0.86 咖啡碱 UVE-PLS 0.0954 0.813 0.1197 0.1078 2.5284 0.9327 0.87 CARS-SVM 0.2389 0.7626 0.1379 0.1344 1.7255 0.9129 0.91 SPA-RF 0.2204 0.6448 0.1273 0.1522 1.3618 0.7826 0.78 2.5.1 最佳模型选择
由表4分析,在含水率预测的三种模型中, UVE-PLS模型的预测集误差RMSEP比较大,CARS-SVM模型的训练集误差RMSEC比较大。UVE-RF的误差合理,同时R2为三种模型中最大,训练集与测试集的相关性均在0.99以上,RMSECV也相对较小,故该模型为最佳含水率预测模型,R2、RMSECV、RPD分别为0.99、0.7615%、10.2093%。
在茶多酚预测的三种模型中,R2除UVE-RF以外,其余两种模型均在0.9以上,RPD均在2%以上,三种模型的误差均较小。RMSECV最小为UVE-RF模型,但该模型的决定系数未达到0.9以上。SPA-PLS模型R2、RPD均小于UVE-SVM模型,且RMSECV大于UVE-SVM模型。故UVE-SVM模型的准确率为最高,R2、RMSECV、RPD分别为0.97、0.3701%、3.5851%。
在氨基酸预测的三种模型中,三种模型的RPD均在20 μg·g−1以上,RMSECV均比较小且相差不大,同时校正集与预测集相关系数也均在0.9以上。R2数值上看CARS-SVM为最高,达到0.9以上,故最佳预测模型为CARS-SVM,R2、RMSECV、RPD分别为0.92、0.723 μg·g−1、25.446 μg·g−1。
在咖啡碱预测中,CARS-SVM模型的R2最高为0.91,但RPD在2%以下,误差过大,表现相对不好。SPA-RF模型的R2和RPD仅为0.78%和1.36%,效果最差。相较而言,UVE-PLS模型的准确率最高,R2高于0.8,RMSECV相对较小,RPD数值也大于2%,数值分别为0.87、0.1197%、2.5284%。
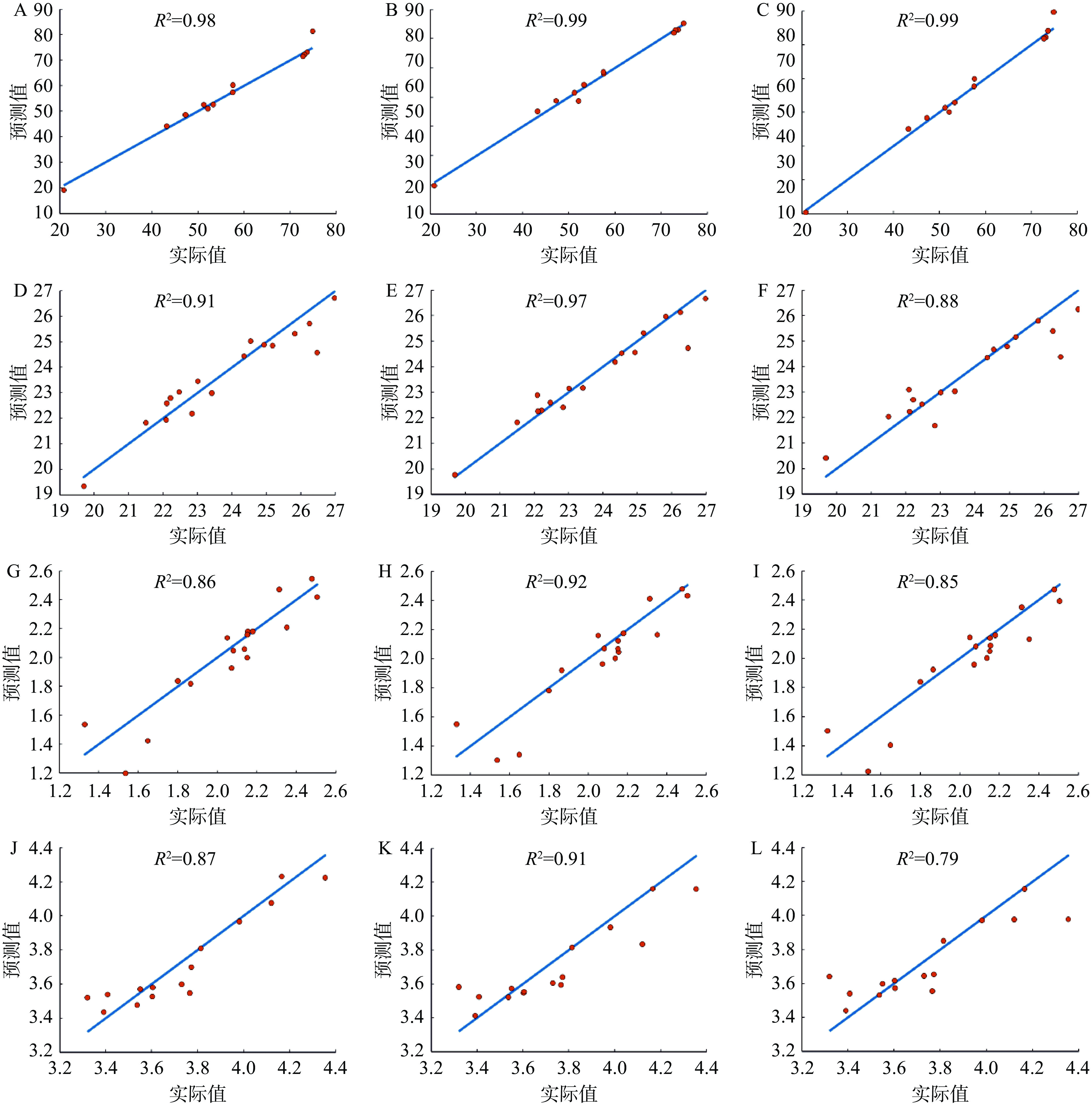
表5为根据表4模型评价参数综合筛选出的各生化成分最优模型。图7显示了预测值与实际值的散点分布,可直观反映出四种指标预测值与真实值的关系。
表 5 最佳建模结果Table 5. The best results of modeling生化成分 最优方法 R2 RMSECV RPD 含水率 UVE-RF 0.99 0.7615 10.2093 氨基酸 CARS-SVM 0.92 0.0723 2.5446 茶多酚 UVE-SVM 0.97 0.3701 3.5851 咖啡碱 UVE-PLS 0.87 0.1197 2.5284 ![]() 图 7 各成分最佳模型测试数据集散点图注:A-含水率UVE-PLS;B-含水率CARS-SVM;C-含水率SPA-RF;D-茶多酚SPA-PLS;E-茶多酚UVE-SVM;F-茶多酚UVE-RF;G-氨基酸CARS-PLS;H-氨基酸CARS-SVM;I-氨基酸SPA-RF;J-咖啡碱UVE-PLS;K-咖啡碱CARS-SVM;L-咖啡碱SPA-RF。Figure 7. Distribution point diagram of best model test data of each component
图 7 各成分最佳模型测试数据集散点图注:A-含水率UVE-PLS;B-含水率CARS-SVM;C-含水率SPA-RF;D-茶多酚SPA-PLS;E-茶多酚UVE-SVM;F-茶多酚UVE-RF;G-氨基酸CARS-PLS;H-氨基酸CARS-SVM;I-氨基酸SPA-RF;J-咖啡碱UVE-PLS;K-咖啡碱CARS-SVM;L-咖啡碱SPA-RF。Figure 7. Distribution point diagram of best model test data of each component2.5.2 建模结果分析
从模型结果来看,在四种指标的最佳建模中,R2数值均在0.8以上,RMSECV均较小,RPD数值均大于2,均达到模型预期的效果,证明利用高光谱技术与绿茶原料生化成分建模的可行性,也表明茶叶原料高光谱特征能够为快速、便捷、无损地检测含水率、游离氨基酸、茶多酚和咖啡碱四种成分,对于原料加工实时检测滋味品质指标有着一定的指导作用。
本试验在处理数据时,均采用同一种预处理方法,从而探讨变量筛选与模型之间组合效果的优劣。在特征筛选中,三种指标的特征提取方法都是UVE算法,只有一种为CARS算法而且使用SPA算法的最佳模型却一个都没有。原因可能为特征提取算法筛选出的特征波长质量和数量对于模型有间接影响,从而导致四种指标的最优模型各不相同。从算法原理上分析,UVE算法是通过PLSR回归系数稳定性的分析进行变量筛选,因此可避免模型过度拟合的产生,从而提高预测能力。CARS算法通过自适应重加权采样技术(ARS)选择出PLSR模型中回归系数绝对值较大的波长点,在一定程度上可有效选择与茶叶原料成分相关的最优波长组合。SPA算法对于共线的变量选择较好,但是可能茶叶光谱数据中的有效光谱信息是非共线的,提取算法丢失部分有效信息,导致模型性能下降,这与于雷等[33]结论一致。
本文通过全波段多算法建模分析,提高了模型精度,解决以往单一模型或单一方法建模的局限性问题,发现建模算法的特点决定与成分之间的相关性,对三种建模方法的比较,发现不同数据的最优模型是不同的。含水率的预测效果非常好,决定系数在0.99以上,优于吴伟斌等[34]仅使用SPA一种特征提取方法进行PLS算法建模的结果,原因可能是UVE算法保留了大部分的特征从而使RF模型更加准确,表明含水率与茶叶高光谱反射率有强相关性。茶多酚、氨基酸预测结果虽次之,但均优于陈雅君等[35]的结果。原因可能由于其使用一元线性回归模型对于异常值比较敏感,导致模型效果下降,而本研究采用SVM算法可以充分利用光谱数据中的线性和非线性信息,对异常值具有鲁棒性、易于实现决策模型的更新,因此结果更优。咖啡碱预测结果虽相对较差,但相关性仍较高,且结果误差要比白晓丽等[36]利用近红外光谱建立的PLS模型更小,原因可能为PLS算法只能利用光谱数据中的线性信息,而非线性信息却利用不了,模型效果还有较大上升空间。
加工是影响茶叶品质的重要因素,如何在加工中快速准确地反馈茶叶的品质指标,是茶叶加工方面的技术瓶颈。本试验只属于绿茶加工质量检测的初步性研究,改善之处大致有两点。其一,由于影响茶叶原料的生化成分不仅有加工一个要素,年份和品种等都有一定程度上的影响,本文模型的普适性还需要进一步研究。其二,本文只是利用高光谱技术对于茶叶整个加工流程的四种生理生化成分进行建模分析,但是对于每个加工步骤的深入挖掘还不够。在未来,可针对某个加工步骤做专项研究,增加茶叶生化成分研究的种类,并提高模型建立的样本总量,为提高加工品质提供更完善的理论依据。
3. 结论
本文通过光谱预处理以及特征波段选择,建立了与茶叶加工原料的含水率、游离氨基酸、茶多酚、咖啡碱四项指标的高光谱数据模型,最佳预测模型分别为UVE-RF、CARS-SVM、UVE-SVM、UVE-PLS,模型的决定系数R2分别为0.99、0.92、0.97、0.87。模型均达到了预期的效果,精度很高。通过模型的研究与应用,有望实现茶叶加工原料的智能筛选和解决当今“看茶制茶”的不准确、费时费力的难题,从而提高整体的茶叶加工品质,为茶叶加工的智能化发展提供了新方法与新思路。
-
![]()
图 5 经MSC+二阶导数微分法+S-G平滑处理后的光谱曲线
Figure 5. Spectral curve after MSC+second derivative differentiation+S-G smoothing
![]()
图 6 特征波段分布
注:A-含水率UVE;B-含水率CARS;C-含水率SPA;D-茶多酚UVE;E-茶多酚CARS;F-茶多酚SPA;G-氨基酸UVE;H-氨基酸CARS;I-氨基酸SPA;J-咖啡碱UVE;K-咖啡碱CARS;L-咖啡碱SPA。
Figure 6. Characteristic band distribution
![]()
图 7 各成分最佳模型测试数据集散点图
注:A-含水率UVE-PLS;B-含水率CARS-SVM;C-含水率SPA-RF;D-茶多酚SPA-PLS;E-茶多酚UVE-SVM;F-茶多酚UVE-RF;G-氨基酸CARS-PLS;H-氨基酸CARS-SVM;I-氨基酸SPA-RF;J-咖啡碱UVE-PLS;K-咖啡碱CARS-SVM;L-咖啡碱SPA-RF。
Figure 7. Distribution point diagram of best model test data of each component
表 1 各加工步骤的样品数据平均值
Table 1 Average value of sample data for each processing step
加工步骤 含水率(%) 茶多酚(%) 氨基酸(×10 μg·g−1) 咖啡碱(%) 茶鲜叶 79.28 23.16 1.86 3.45 摊晾1 h 73.17 24.85 2.12 3.97 摊晾2 h 72.34 26.06 2.49 4.21 摊晾3 h 73.19 24.17 2.16 4.21 摊晾4 h 71.83 22.18 2.19 3.80 杀青180 ℃ 59.23 25.58 1.22 3.55 杀青200 ℃ 57.38 26.80 1.50 4.07 杀青220 ℃ 53.31 24.54 1.39 3.53 杀青240 ℃ 52.78 24.56 1.47 3.49 杀青260 ℃ 48.12 24.24 1.81 3.69 杀青280 ℃ 44.16 25.34 2.00 3.70 揉捻20 min 51.01 22.39 2.45 3.75 揉捻40 min 50.77 21.66 2.33 3.40 揉捻60 min 51.63 22.24 2.50 3.59 滚筒做形 20.40 19.47 2.03 4.26 炒锅做形 15.45 25.15 2.19 3.24 干燥70 ℃ 23.14 2.08 3.57 干燥80 ℃ 21.81 2.08 3.62 干燥90 ℃ 22.88 2.14 3.54 干燥100 ℃ 22.53 2.12 3.38  下载: 导出CSV
下载: 导出CSV
表 2 训练集与测试集的生化成分统计分析
Table 2 Statistical Analysis of biochemical components of training set and test set
生化成分 光谱图片数量(张) 总样本(个) 训练样本(个) 预测样本(%) 最大值 最小值 均值 标准差 含水率 16 48 36 12 83.72 15 54.64 17.45 茶多酚 20 60 43 17 26.97 18.86 23.64 1.8 氨基酸 20 60 43 17 2.54 0.83 2.01 0.37 咖啡碱 20 65 50 15 5.01 2.84 3.7 0.34 注:咖啡碱测量时,为保障数据准确性,故多测量5组数据,一并用于建模。
下载: 导出CSV
表 3 波段筛选结果
Table 3 Band screening results
生化成分 筛选方法 波长数目 波长范围 含水率 UVE 84 400~449,463~494,545~563,642~670,687~735,770~783,814~866,935~953,1001~1004 CARS 32 401,583~604,642~659,677~683,704~708,766~773,797~808,835~839,863~870,918 SPA 14 442,466,511,556,608,677,701,721,787,839,863,890,935,987 茶多酚 UVE 55 680~708,821~915,935~994 CARS 40 559,597~608,649~663,683~689,701~708,721~749,766~777,787~797,821~877,939~942,966~980,997~1004 SPA 16 404,494,532,639,690,711,725,746,770,801,856,873,894,921,949,973 咖啡碱 UVE 28 507,511,756~763,901~936,966~1004 CARS 18 432,452,459,521,590,621,628,783,787,821,835,842,887,894,973,984,987,1004 SPA 11 442,466,677,714,750,787,842,866,897,935,977 氨基酸 UVE 48 476~497,542~566,649~680,877~918,953~970 CARS 15 418~421,452~459,473,563,573,608~614,659~663,963,970 SPA 14 401,442,490,514,556,659,680,701,721,752,790,835,887,942
下载: 导出CSV
表 4 模型结果汇总表
Table 4 Summary of model results
生化成分 模型 训练集 交互验证均方根误差 RMSECV 预测集 均方根误差 RMSEC 相关系数 Rcal 均方根误差 RMSEP 相对分析误差 RPD 相关系数 Rp 决定系数 R2 含水率 UVE-PLS 0.0155 0.9983 0.5483 2.2716 7.3261 0.9914 0.98 CARS-SVM 2.0253 0.9941 1.0458 1.3819 11.4795 0.9959 0.99 UVE-RF 1.5934 0.9936 0.7615 1.4747 10.2093 0.9902 0.99 茶多酚 SPA-PLS 0.0929 0.9031 0.4427 0.6184 2.9274 0.9524 0.91 UVE-SVM 0.6206 0.9356 0.3701 0.5049 3.5851 0.9694 0.97 UVE-RF 0.6033 0.892 0.3598 0.7321 2.226 0.8814 0.88 氨基酸 CARS-PLS 0.0747 0.9405 0.0764 0.1382 2.6253 0.9264 0.86 CARS-SVM 0.1212 0.9478 0.0723 0.1347 2.5446 0.9247 0.92 SPA-RF 0.1148 0.9102 0.0684 0.1399 2.4942 0.8595 0.86 咖啡碱 UVE-PLS 0.0954 0.813 0.1197 0.1078 2.5284 0.9327 0.87 CARS-SVM 0.2389 0.7626 0.1379 0.1344 1.7255 0.9129 0.91 SPA-RF 0.2204 0.6448 0.1273 0.1522 1.3618 0.7826 0.78
下载: 导出CSV
表 5 最佳建模结果
Table 5 The best results of modeling
生化成分 最优方法 R2 RMSECV RPD 含水率 UVE-RF 0.99 0.7615 10.2093 氨基酸 CARS-SVM 0.92 0.0723 2.5446 茶多酚 UVE-SVM 0.97 0.3701 3.5851 咖啡碱 UVE-PLS 0.87 0.1197 2.5284
下载: 导出CSV
-
[1] 曹佳. 浅谈我国茶叶加工的发展现状、趋势及创新[J]. 福建茶叶,2021,43(11):35−36. [CAO J. On the development status, trend and innovation of tea processing in China[J]. Tea in Fujian,2021,43(11):35−36. doi: 10.3969/j.issn.1005-2291.2021.11.017 [2] 田有文, 林磊, 宋士媛, 等. 基于DIQA的腐烂蓝莓高光谱特征波长图像选取方法[J]. 沈阳农业大学学报, 2022, 53(2): 187-195. TIAN Y W, LIN L, SONG S Y, et al. Hyperspectral characteristic wavelength image selection method of decayed blueberry based on DIQA[J]. Journal of Shenyang Agricultural University, 2022, 53(2): 187-195.
[3] 郭昊蔚, 李春霖, 龚淑英, 等. 光谱技术在茶叶理化指标检测中的研究进展[J]. 茶叶,2019,45(1):9−12. [GUO H W, LI C L, GONG S Y, et al. Research progress of spectroscopy in the detection of tea physical and chemical characteristics[J]. Journal of Tea,2019,45(1):9−12. doi: 10.3969/j.issn.0577-8921.2019.01.007 [4] AN T, HUANG W Q, TIAN X, et al. Hyperspectral imaging technology coupled with human sensory information to evaluate the fermentation degree of black tea[J]. Sensors and Actuators:B Chemical,2022,366:131994. doi: 10.1016/j.snb.2022.131994
[5] CHEN Q S, ZHAO J W, CAI J R, et al. Estimation of tea quality level using hyperspectral imaging technology[J]. Acta Optica Sinica,2008,28(4):669−674. doi: 10.3788/AOS20082804.0669
[6] PAUL J C, JENNIFER L D, DAVID L P. Estimating the foliar biochemical concentration of leaves with reflectance spectrometry[J]. Remote Sensing of Environment,2001,76(3):349−359. doi: 10.1016/S0034-4257(01)00182-1
[7] HONG Z, HE Y. Rapid and nondestructive discrimination of geographical origins of longjing tea using hyperspectral imaging at two spectral ranges coupled with machine learning methods[J]. Applied Sciences,2020,10(3):1173−1184. doi: 10.3390/app10031173
[8] 孙耀国, 林敏, 吕进, 等. 近红外光谱法测定绿茶中氨基酸、咖啡碱和茶多酚的含量[J]. 光谱实验室,2004(5):940−943. [SUN Y G, LIN M, LYU J, et al. Determination of the contents of free amino acids, caffeine and tea polyphenols in green tea by fourier transform near-infrared spectroscopy[J]. Chinese Journal of Spectroscopy Laboratory,2004(5):940−943. doi: 10.3969/j.issn.1004-8138.2004.05.033 [9] 陈义, 袁丁, 孙慕芳. 信阳毛尖茶叶感官品质与化学成分的相关性分析[J]. 江苏农业科学,2014,42(11):342−344. [CHEN Y, YUAN D, SUN M F. Correlation analysis between sensory quality and chemical components of Xinyang maojian tea[J]. Jiangsu Agricultural Sciences,2014,42(11):342−344. doi: 10.15889/j.issn.1002-1302.2014.11.122 [10] LI L, PENG Y K, LI Y Y, et al. A new scattering correction method of different spectroscopic analysis for assessing complex mixtures[J]. Analytica Chimica Acta,2019,1087:20−28. doi: 10.1016/j.aca.2019.08.067
[11] XU M X, CHU X Y, FU Y S, et al. Improving the accuracy of soil organic carbon content prediction based on visible and near-infrared spectroscopy and machine learning[J]. Environmental Earth Sciences,2021,80(8):326.1−326.10.
[12] 冯蕾, 陈锡芹, 程祖顺, 等. 二阶导数光谱法定量分析凝灰岩石粉对不同侧链长度聚羧酸减水剂吸附性[J]. 光谱学与光谱分析,2019,39(9):2788−2793. [FENG L, CHEN X Q, CHENG Z S, et al. Quantitative analysis for adsorption of polycarboxylate superplasticizer with different side-chain length on tuff powder using second derivative spectrometry[J]. Spectroscopy and Spectral Analysis,2019,39(9):2788−2793. [13] 郭斗斗, 黄绍敏, 张水清, 等. 多种潮土有机质高光谱预测模型的对比分析[J]. 农业工程学报,2014,30(21):192−200. [GUO D D, HUANG S M, ZHANG S Q, et al. Comparative analysis of various hyperspectral prediction models of fluvo-aquic soil organic matter[J]. Transactions of the Chinese Society of Agricultural Engineering,2014,30(21):192−200. doi: 10.3969/j.issn.1002-6819.2014.21.023 [14] 赵强, 张工力, 陈星旦. 多元散射校正对近红外光谱分析定标模型的影响[J]. 光学精密工程,2005(1):53−58. [ZHAO Q, ZHANG G L, CHENG X D. Effects of multiplicative scatter correction on a calibration model of near infrared spectral analysis[J]. Optics and Precision Engineering,2005(1):53−58. doi: 10.3321/j.issn:1004-924X.2005.01.010 [15] 黄凌霞, 吴迪, 金航峰, 等. 基于变量选择的蚕茧茧层量可见-近红外光谱无损检测[J]. 农业工程学报,2010,26(2):231−236. [HUANG L X, WU D, JIN H F, et al. Non-destructive detection of cocoon shell weight based on variable selection by visible and near infrared spectroscopy[J]. Transactions of the Chinese Society of Agricultural Engineering,2010,26(2):231−236. [16] ZOU X B, ZHAO J W, MALCOLM J W, et al. Variables selection methods in near-infrared spectroscopy[J]. Analytica Chimica Acta,2010,667(1):14−32.
[17] LU H X, ZHANG J, LI L Q, et al. Least angle regression combined with competitive adaptive re-weighted sampling for NIR spectral wavelength selection[J]. Spectroscopy and Spectral Analysis,2021,41(6):1782−1788.
[18] 曲歌, 陈争光, 张庆华. 基于无信息变量消除法的水稻种子发芽率测定[J]. 江苏农业学报,2019,35(5):1015−1020. [QU G, CHEN Z G, ZHANG Q H. Study on germination rate of rice seed based on uninformation variable elimination method[J]. Jiangsu Agricultural Journal,2019,35(5):1015−1020. doi: 10.3969/j.issn.1000-4440.2019.05.002 [19] 彭海根, 金楹, 詹莜国, 等. 近红外光谱技术结合竞争自适应重加权采样变量选择算法快速测定土壤水解性氮含量[J]. 分析测试学报,2020,39(10):1305−1310. [PENG H G, JIN Y, ZHAN X G, et al. Quantitative determination of hydrolytic nitrogen content in soil by infrared spectroscopy combined with adaptive reweighted sampling variable selection algorithm[J]. Journal of Instrumental Analysis,2020,39(10):1305−1310. doi: 10.3969/j.issn.1004-4957.2020.10.019 [20] 赵静远, 熊智新, 宁井铭, 等. 小波变换结合连续投影算法优化茶叶中咖啡碱的近红外分析模型[J]. 分析科学学报,2021,37(5):611−617. [ZHAO J Y, XIONG Z X, NING J M, et al. Wavelet transform combined with spa to optimize the near-infrared analysis model of caffeine in tea[J]. Journal of Analytical Science,2021,37(5):611−617. [21] ANJOS O, CALDEIRA I, FERNANDES T A, et al. PLS-R Calibration models for wine spirit volatile phenols prediction by near-infrared spectroscopy[J]. Sensors,2021,22(1):286. doi: 10.3390/s22010286
[22] LI D Y, MA Z M. Residual attention learning network and svm for malaria parasite detection[J]. Multimedia Tools and Applications,2022,81(8):10935−10960. doi: 10.1007/s11042-022-12373-6
[23] JEVŠENAK J, SKUDNIK M. A random forest model for basal area increment predictions from national forest inventory data[J]. Forest Ecology and Management,2021,479:118601. doi: 10.1016/j.foreco.2020.118601
[24] UYEH D D, IYIOLA O, MALLIPEDDI R, et al. Grid search for lowest root mean squared error in predicting optimal sensor location in protected cultivation systems[J]. Frontiers in Plant Science,2022,13:920284. doi: 10.3389/fpls.2022.920284
[25] 李丹, 黄钰辉, 孙中宇, 等. 不同树种叶片养分含量提取的高光谱方法及精度评价[J]. 热带地理, 2020, 40(2): 175-183. LI D, HUANG Y H, SUN Z Y, et al. Development and accuracy assessment of a hyperspectral data-based model for leafnutrient content extraction in wetland tree species[J]. Tropical Geography, 2020, 40(2): 175-183.
[26] CHEN S Z, GAO Y, FAN K, et al. Prediction of drought-induced components and evaluation of drought damage of tea plants based on hyperspectral imaging[J]. Frontiers in Plant Science,2021,12:695102. doi: 10.3389/fpls.2021.695102
[27] 刘建军, 陈义, 郭桂义, 等. 不同摊放时间和杀青温度对夏季绿茶品质的影响[J]. 河南农业科学,2011,40(5):74−76. [LIU J J, CHENG Y, GUO G Y, et al. Effects of laying time and de-enzyming on the quality of summer green tea[J]. Journal of Henan Agricultural Sciences,2011,40(5):74−76. doi: 10.3969/j.issn.1004-3268.2011.05.018 [28] 宛晓春. 茶叶生物化学[M]. 第3版. 北京: 中国农业出版社, 2003: 108−110. WAN X C. Biochemistry of tea[M]. 3th ed. Beijing: China Agricultural Press, 2003: 108−110.
[29] 李晓丽, 魏玉震, 徐劼, 等. 基于高光谱成像的茶叶中EGCG分布可视化[J]. 农业工程学报,2018,34(7):180−186. [LI X L, WEI Y Z, XU J, et al. EGCG distribution visualization in tea leaves based on hyperspectral imaging technology[J]. Transactions of the Chinese Society of Agricultural Engineering,2018,34(7):180−186. [30] 夏小欢, 陈旭东, 付杰, 等. 揉捻压力大小对香茶生化成分与感官品质的影响[J]. 现代农业科技,2021(23):186−187, 190. [XIA X H, CHEN X D, FU J, et al. Effect of rolling pressure on biochemical components and sensory quality of fragrant tea[J]. Modern Agricultural Sciences and Technology,2021(23):186−187, 190. [31] 宛晓春. 红、绿茶干燥过程的热化学变化[J]. 茶叶科学,1988(2):47−52. [WAN X C. Thermochemical changes of red and green tea during drying[J]. Journal of Tea Science,1988(2):47−52. [32] MAO Y, LI H, WANG Y, FAN K, et al. Prediction of tea polyphenols, free amino acids and caffeine content in tea leaves during wilting and fermentation using hyperspectral imaging[J]. Foods,2022,11(16):2537. doi: 10.3390/foods11162537
[33] 于雷, 洪永胜, 周勇, 等. 高光谱估算土壤有机质含量的波长变量筛选方法[J]. 农业工程学报,2016,32(13):95−102. [YU L, HONG Y S, ZHOU Y, et al. Wavelength variable selection methods for estimation of soil organic matter content using hyperspectral technique[J]. Transactions of the Chinese Society of Agricultural Engineering,2016,32(13):95−102. [34] 吴伟斌, 刘文超, 李泽艺, 等. 基于高光谱的茶叶含水量检测模型建立与试验研究[J]. 河南农业大学学报,2018,52(5):818−824. [WU W B, LIU W C, LI Z Y, et al. Study on detection model establishment and experiment of tea water content based on hyperspectral[J]. Journal of Henan Agricultural University,2018,52(5):818−824. [35] 陈雅君. 影响茶叶品质的主要生化指标的高光谱反演研究[D]. 福州: 福建师范大学, 2017. CHENG Y J. Study on hyperspectral inversion of main biochemical indexes affecting tea quality[D]. Fuzhou: Fujian Normal University, 2017.
[36] 白晓丽, 郭卫华, 孔俊豪, 等. 速溶普洱茶中水分、咖啡碱和茶多酚含量近红外光谱快速测定方法的建立[J]. 食品工业科技,2019,40(1):234−238,245. [BAI X L, GUO W H, KONG J H, et al. Establishment of a method for the rapid measurement of moisture, caffeine and tea-polyphenols in instant pu'er tea by near infrared spectroscopy[J]. Science and Technology of Food Industry,2019,40(1):234−238,245.
 下载:
下载:










计量
- 文章访问数:
- HTML全文浏览量:
- PDF下载量:
