


Establishment of Detection Model of Water-injected Meat Based on Low Field Nuclear Magnetic Resonance Transverse Relaxation Spectroscopy
-
摘要: 用直接注射的方式,将猪背最长肌制备成注水比例分别为0、2%、6%、10%和14%的肉样本。利用低场核磁共振(field nuclear magnetic resonance,LF-NMR)技术测量肉样本产生的NMR信号,并将反演后得到的横向弛豫谱参数作为自变量,通过判别分析(Discriminant analysis,DA)和偏最小二乘回归(partial least square regression,PLSR)分析,分别建立注水肉检测模型,并尝试多种可能性的PLSR建模,评估分析模型对较低注水比例的注水肉的检测性能。结果表明,对DA模型进行回代验证和留一交叉验证,模型对注水肉分类的总正确率分别为89.4%和88.2%。采用将杠杆值和学生化残差相结合的方式判别和删除异常数据,用变量投影重要性分析法筛选出6个横向弛豫谱参数作为自变量建立的优化PLSR模型的检测性能最优,校准集决定系数(Rc2)和标准误差(SEV)分别为0.9603和1.0033%,交叉验证的决定系数(Rcv2)和标准误差(SECV)分别为0.9508和1.1169%,预测集决定系数(Rp2)和标准误差(SEP)分别为0.9518和1.1280%。在95%的置信概率下,优化PLSR模型能够预测未知样本中注水百分比的置信区间的最好估计值约为2.256%。表明基于LF-NMR横向弛豫谱建立的DA模型和PLSR模型可以对注水肉进行有效的定性和定量检测。Abstract: The longissimus dorsi in pigs was prepared into the meat samples with water injection ratio of 0%, 2%, 6%, 10% and 14% by direct injection. The NMR signals generated by the meat samples were measured by LF-NMR technique. The transverse relaxation spectrum parameters obtained by inversion were taken as independent variables, combined with discriminant analysis and partial least square regression (PLSR) analysis, the models for detecting water-injected meat were developed, and multiple possibilities for PLSR modeling were attempted. It was showed that the developed discriminant model was validated with calibration set and leave-one-out cross, the total accuracy of the classification of water-injected meat was 89.4% and 88.2%, respectively. By combining the lever value with the student residual, the abnormal data was distinguished and deleted, and the prediction performance of the PLSR model established by using the variable projection importance analysis method to select out six transverse relaxation spectrum parameters as independent variables was optimal, the determination coefficient (Rc2) and standard error (SEV) from calibration set were 0.9603 and 1.0033%, the determination coefficient(Rcv2) and standard error (SECV) from cross validation were 0.9508 and 1.1169%, the determination coefficient(Rp2) and standard error (SEP) from prediction set were 0.9518 and 1.1280%, respectively. The best estimate of the confidence interval capable of predicting the percentage of water injection in unknown samples was about 2.256% at 95% confidence probability. The results showed that the DA model and PLSR model based on LF-NMR transverse relaxation spectrum could be used for qualitative and quantitative detection of water-injected meat.
-
注水肉作为食物掺假的一种方式,不仅降低了肉的品质,扰乱了正常的市场秩序,还对消费者的健康产生危害[1-2]。一些不法商人为了牟利,仍然在生产和销售注水肉。为了解决注水肉禁而不止的问题,针对国内现行畜禽肉水分限量标准和检测方法不能适应新变化的现实,需要开展对畜禽肉水分限量标准及检测方法的研究[3]。
近年来,注水肉检测方法的研究主要集中在基于光谱分析技术和低场核磁共振(LF-NMR)技术这两个方向上。光谱分析技术作为一种快速、无损的检测方法不仅被应用于注水肉的检测研究[4-7],也被用于肉制品的其他掺假识别研究[8]。采用LF-NMR技术得到的横向弛豫谱,能够反映食品和生物体系中处在不同物理化学环境下水的横向弛豫特性。理化环境、水含量及水分布的变化都对横向弛豫谱产生影响[9]。横向弛豫谱可以对食品和生物体系中的水含量及水分布进行快速、无损、高灵敏度的分析,因此被广泛应用于食品掺假的识别[10-11]、食品含水率的预测[12-13]、影响食品中水分分布因素的分析等[14]。对正常羊肉和随机注入不同比例水的羊肉进行LF-NMR检测,结合主成分分析及逐步线性判别分析能够在一定程度上对不同的羊肉进行定性区分[15]。在肉糜中注水,根据注水比例0、2%~14%、16%~30%、32%~40%将肉样品分为原料肉、轻度、中度、重度注水肉糜,在单组分和多组分弛豫特性分析的基础上结合判别分析可对四种不同程度的注水肉糜进行定性识别[16]。利用LF-NMR技术对注水肉进行检测的研究主要集中在定性检测,对低注水比例的注水肉的定量检测研究鲜有报道。
本研究以新鲜的猪背最长肌作为注水对象,采用CPMG脉冲序列获得NMR信号,经反演后得到横向弛豫谱及相对应的16个横向弛豫谱参数数据。分别用判别分析(DA)和偏最小二乘回归(PLSR)建立注水肉定性和定量检测模型,尝试多种可能性的PLSR建模。评估分析模型检测注水肉的性能,确定最优的PLSR模型,以PLSR模型预测注水比例的置信区间为依据,分析DA模型在识别注水肉时发生误判的原因,为基于LF-NMR技术的注水肉的定性定量检测提供数据支撑。
1. 材料与方法
1.1 材料与仪器
取自17头猪的新鲜的背最长肌 分9次购于海口市城西农贸市场。
MesoMR23-060H-I型核磁共振成像分析仪 苏州纽迈分析仪器股份公司;JA1003型电子天平 上海良平仪器仪表有限公司;H.SWX-420BS型电热恒温水温箱 上海新苗医疗器械制造股份公司;100 μL微量注射器 上海高鸽工贸有限公司。
1.2 实验方法
1.2.1 样本制备
采用注射器直接向肌肉注水的方式制备注水肉样本。将一条猪背最长肌制备成15个肉样本,每个肉样本的质量为10±0.1 g,将肉样本切成方形。三个肉样本为一组,共五组。其中没有注入水的一组作为正常肉样本。另外四组作为注水肉样本,分别按原始肉样本质量的2%、6%、10%和14%注射蒸馏水。共制备255个肉样本。将制备好的每个样本单独装入自封袋中,放置在4 ℃冰箱中冷藏保存6 h。
1.2.2 测量NMR信号
从冰箱中取出冷藏6 h的样本,将自封袋中的样本放入32 ℃的恒温水箱中,放置20 min,使肉样本温度达到32 ℃。再将肉样本置于低场核磁共振成像分析仪的测试床上,选用CPMG脉冲序列测量肉样本产生的NMR信号,每个样本重复测量2次。CPMG脉冲序列参数设置如下:前置放大增益PRG=2,重复采样等待时间TW=6000 ms,回波时间TE=0.22 ms,回波个数NECH=18000,采样频率SW=100 kHz,射频延时时间RFD=0.1 ms,模拟增益RG1=20.0 db,数字增益DRG1=3,重复激励次数NS=8。
1.2.3 判别分析
判别分析是根据已知类别的样本所提供的信息,总结分类的规律性,建立判别公式和准则,再根据判别函数判别新样本所属类别。判别分析要求预测变量之间相互独立、无多重共线性[17]。判别分析常被用于将食品按不同品质进行分类[18]。将实验肉样本按注水比例分为五个类别,第1类别是正常肉,第2~5个类别分别是注水比例为2%、6%、10%和14%注水肉。从16个横向弛豫谱参数中选择预测变量,对横向弛豫谱参数数据进行训练,建立对注水肉进行分类的DA模型。
1.2.4 偏最小二乘回归
PLSR是一种用线性多变量模型将解释变量和响应变量两个数据矩阵联系起来的多元统计方法,能够在解释变量存在多重共线性的条件下进行回归建模,并适用于样本量较少的情况[19]。PLSR模型的拟合度和预测精度可以用决定系数和标准误差来评估[20-21]。将实验样本分为校准集和预测集,根据校准集建立的校准模型对响应变量进行预测,预测值与测量值的相关程度由决定系数决定。决定系数定义为:
R2=1−PRESSSS=1−n∑i=1(yi−ˆyi)2n∑i=1(yi−ˉyi)2 (1) 预测精度由标准误差决定,标准误差定义为:
SE=√n∑i=1(yi−ˆyi)2n−1 (2) 上两式中:n为校准集样本的个数;PRESS为残差平方和;
yi 为第i个样本的测量值;ˆyi 为第i个样本的预测值;ˉy 为响应变量的平均值。用预测集对校准模型作外部数据验证时,预测的精度由预测标准误差决定,定义预测标准误差为SEP=√n∑i=1(yi−ˆyi−bias)2n−1 (3) 式中:
bias=1mm∑i=1(yi−ˆyi) ,其中n为预测集样本的个数。在进行PLSR建模时,选择横向弛豫谱参数作为自变量,注水百分比作为响应变量,进行多种可能性的尝试,建立多种检测注水肉的PLSR模型。1.3 数据处理
采用MesoMR23-060H-I型核磁共振成像分析仪提供的核磁共振分析软件Ver4.0对核磁共振测量数据进行多组分反演,得到每个肉样本的横向弛豫谱及相对应的16个横向弛豫谱参数值。反演参数选择如下:参与反演的信号点数为2000,抽样方式为随机抽样,滤波档位为3,弛豫时间最小值0.01 ms,弛豫时间最大值为10000 ms,弛豫时间点数为200,反演方法为SIRT,迭代次数为10000。完成反演运算后计算出每组样本的16个横向弛豫谱参数的平均值,作为该组样本的横向弛豫谱参数值。共得到85组横向弛豫谱参数数据。
采用IBM SPSS Statistics 24 (International Business Machines Corp., Armonk, New York, U.S.)软件进行判别分析建模和相关数据分析,并对DA模型进行回代验证和留一交叉验证。
采用MATLAB R2014a(The MathWorks, Inc., Natick, Massachusetts, United States)软件编程实现PLSR建模、模型验证及相关数据处理。
2. 结果与分析
2.1 肉样本的核磁共振横向弛豫谱及横向弛豫谱参数
图1是取自同一头猪的具有不同注水比例的5个肉样本的横向弛豫谱图。实验中绝大多数肉样本的横向弛豫谱由三个峰组成,少数肉样本多于三个峰。这与许多学者的研究结果一致[22-23]。在肉中存在三种不同状态的水,分别是结合水、不易流动水和自由水,对应于横向弛豫谱的三个峰[24]。在16个横向弛豫谱参数中,总峰面积用S表示,反映肉样本中水分的总含量。三个峰的面积分别用S21、S22、S23表示,反映肉样本中结合水、不易流动水和自由水的含量。结合水、不易流动水和自由水峰面积占总峰面积的比例分别用P21、P22、P23表示。三种状态的水具有不同的横向弛豫时间,T21、T22和T23分别表示结合水、不易流动水和自由水的横向弛豫时间,它们在一定范围内变化。三个峰在起始点、顶点和结束点的横向弛豫时间分别用下标b、m及e区分。
![]() 图 1 5种不同注水比例的肉样本的横向弛豫谱Figure 1. Transverse relaxation spectroscopy of five kinds of meat samples with different percentage of injected water
图 1 5种不同注水比例的肉样本的横向弛豫谱Figure 1. Transverse relaxation spectroscopy of five kinds of meat samples with different percentage of injected water正常肉样本和不同注水比例的肉样本的横向弛豫谱存在差异,如图1所示。肉中三种不同状态的水表现出的差异程度不同,其中自由水表现出的差异最明显。
2.2 检测注水肉的DA模型的建立
2.2.1 选择预测变量
横向弛豫谱参数中不同参数区分注水比例的能力不同,表1是类别平均值等同性检验的结果。Wilks’Lambda值在0~1之间,数值越小类别之间的差异越大,区分能力越强。S、S23、P23、P22、T23e是区分注水比例能力较强的参数,可以选择它们作为建立DA模型的预测变量。但考虑到判别分析要求预测变量无多重共线性,而交叉散点图表明S23、P23、P22之间有很强的线性相关性,只能取其中的一个作为预测变量。综合考虑后,最终选择S、P23、及T23e作为建立DA模型的预测变量。
表 1 类别平均值等同性检验结果Table 1. Tests of equality of class means预测变量 Wilks’ Lambda F P S 0.094 192.646 0.000 S23 0.186 87.740 0.000 P23 0.207 76.719 0.000 P22 0.259 57.343 0.000 T23e 0.447 24.765 0.000 T22e 0.517 18.652 0.000 S22 0.583 14.286 0.000 T23m 0.638 11.347 0.000 P21 0.666 10.041 0.000 T21e 0.670 9.843 0.000 T23b 0.776 5.761 0.000 T22m 0.785 5.485 0.001 T21m 0.800 4.997 0.001 T21b 0.844 3.693 0.008 T22b 0.908 2.033 0.098 S21 0.936 1.374 0.250 2.2.2 建立DA模型
遵循Bayes准则进行判别分析,根据分类函数系数表,建立五个Bayes函数式:
B1=0.143S+475.490P23−0.007T23e−1105.945 B2=0.148S+520.929P23−0.035T23e−1170.363 B3=0.156S+617.878P23−0.046T23e−1305.252 B4=0.165S+744.277P23−0.035T23e−1467.173 B5=0.171S+836.999P23−0.015T23e−1586.353 将每个肉样本的测量值S、P23、T23e分别代入到5个判别函数式中,算出得分值,该肉样本被归入到得分值最大的类别中,实现对肉样本的判别归类。
2.2.3 DA模型的验证
用回代验证和留一交叉验证对DA模型的判别效果和稳定性进行检验。表2给出了用两种验证方法分别进行验正的结果。从表2可以看出,回代验证发生了9个错判,总判别正确率为89.4%。其中5个错判发生在正常肉与2%的注水肉之间,4个错判发生在10%的注水肉与14%的注水肉之间。留一交叉验证发生了10个错判,总判别正确率为88.2%。错判发生的情况与回代验证类似。回代验证和留一交叉验证的正确率较高且非常接近,说明建立的模型是有效和稳定的。错判全部发生在相邻的类别之间,有必要通过定量分析找到判别的误差范围。
表 2 回代验证与交叉验证的结果Table 2. Results of two verification methods验证方法 类别 预测类别的样本数 总数 1 2 3 4 5 回代验证 1 15 2 0 0 0 17 2 3 14 0 0 0 17 3 0 0 17 0 0 17 4 0 0 0 16 1 17 5 0 0 0 3 14 17 交叉验证 1 15 2 0 0 0 17 2 3 14 0 0 0 17 3 0 0 17 0 0 17 4 0 0 0 15 2 17 5 0 0 0 3 14 17 2.3 检测注水肉的PLSR模型的建立
2.3.1 基于全部实验数据建立的PLSR模型
将85组横向弛豫谱参数数据全部作为校准集。在16个横向弛豫谱参数中提取10个成分,图2显示对注水比例的解释方差的百分比与提取的成分数之间的关系曲线。前三个成分可以累计解释注水比例方差的93.7%。当提取成分数量为4个甚至更多时,对注水比例解释的累计方差几乎不变。图3显示了交叉验证的标准误差(SECV)与成分数的关系,提取3个成分时得到较小的SECV,再增加成分数SECV几乎不变。因此,提取三个成分就可以解释注水比例的绝大部分方差,并得到最小的交叉验证标准误差。
![]() 图 2 对注水比例解释方差的百分比与提取的成分数之间的关系Figure 2. The relationship between the percentage of explained variance and number of extracted components
图 2 对注水比例解释方差的百分比与提取的成分数之间的关系Figure 2. The relationship between the percentage of explained variance and number of extracted components![]() 图 3 交叉验证的标准误差与成分数之间的关系Figure 3. The relationship between SECV and the number of components
图 3 交叉验证的标准误差与成分数之间的关系Figure 3. The relationship between SECV and the number of components在横向弛豫谱参数中提取3个成分,利用偏最小二乘回归建立注水比例与横向弛豫谱参数之间相互关系的PLSR模型。通过校准集数据的验证与留一交叉验证,对所建立的PLSR模型的性能进行评估[25]。直接将校准集的横向弛豫谱参数的测量值输入PLSR模型,输出相对应的注水百分比的预测值,利用式(1)和式(2)计算出校准集决定系数Rc2=0.9371,校准标准误差SEC=1.2922%。将校准集中的第i个样本取出,用剩余的(n−1)个样本重新建立模型,代入样本i的横向弛豫谱参数的测量值,得到样本i的注水百分比的预测值。对每个样本重复上述计算。再根据式(1)和式(2)计算出留一交叉验证的决定系数Rcv2=0.9226,交叉验证的标准误差SECV=1.4333%。PLSR模型对校准集的预测结果如图4所示。该PLSR模型的Rc2、Rcv2均大于0.9,说明模型在校准集中对注水百分比解释方差的比率较高。SEC、SECV较小,表明该模型在校准集中具有较好的预测注水比例的能力。通过校准集数据验证与留一交叉验证的结果非常接近,所建模型没有过度拟合,具有较好的稳定性。
![]() 图 4 PLSR模型的校准集样本注水比例的预测值与测量值之间的相关关系Figure 4. The correlation between the predicted value and the measured value of water injection percentage in the calibration set using PLSR model
图 4 PLSR模型的校准集样本注水比例的预测值与测量值之间的相关关系Figure 4. The correlation between the predicted value and the measured value of water injection percentage in the calibration set using PLSR model2.3.2 基于部分实验数据建立的PLSR模型
为了评价模型的适应性,即评价模型对未来新数据进行预测的能力,需要用外部数据对模型进行验证。将总实验样本分为两部分,其中50条数据构成校准集,剩余的35条数据构成预测集。用校准集作为训练样本建立PLSR模型,预测集作为外部数据对PLSR校准模型进行验证。
首先对PLSR校准模型进行校准集数据验证和留一交叉验证,计算出校准集决定系数、校准标准误差、交叉验证的决定系数以及交叉验证的标准误差分别为:Rc2=0.9353,SEC=1.3162%,Rcv2=0.9086,SECV=1.5646%。再对PLSR校准模型进行外部验证。将预测集的横向弛豫谱参数的测量值输入PLSR校准模型中,输出测试集样品的注水百分比的预测值,根据式(1)计算预测集决定系数为Rp2=0.9240。再根据式(3)计算预测标准误差为,SEP=1.4718%。PLSR模型对校准集和预测集的预测结果如图5所示。决定系数Rc2、Rcv2、Rp2接近,均大于0.9,标准误差SEC、SEP、SECV较小且接近。基于部分实验样本建立的PLSR模型也具有较好的拟合度、稳定性及预测精度。将基于较少样本数建立的PLSR模型与基于较多样本数建立的PLSR模型的统计参数进行比较,发现基于更多样本建立的模型,其性能优于基于较少样本建立的模型。SEP较小,说明PLSR校准模型具有较好的适应性和预测精度,能够比较精确地对未用于建模的样本进行预测。在95%的置信概率下,PLSR模型对预测集样本预测注水比例的置信区间约为2×SEP=2.9436%[26]。
![]() 图 5 PLSR模型对校准集和预测集注水百分比进行预测的值与实测值的关系Figure 5. The relationship between the predicted value and the measured value of water injection percentage of calibration set and prediction set using PLSR model
图 5 PLSR模型对校准集和预测集注水百分比进行预测的值与实测值的关系Figure 5. The relationship between the predicted value and the measured value of water injection percentage of calibration set and prediction set using PLSR model2.3.3 优化PLSR模型
在用统计方法建立模型之前,先对实验数据进行预处理,排除异常值,可提高所建模型的预测精度。对异常数据的检测可采用将杠杆值和学生化残差相结合的方式进行。根据因变量的学生化残差图可以识别出因变量的离群点。但是,只有那些对所建模型有强影响力的离群点才能被排除。学生化残差超过+2,低于-2的因变量可认为是离群点[27-29]。
对基于全部实验数据建立的PLSR模型,图6表示85组数据所对应的注水百分比的学生化残差的散点图。标号为35、60及20的三组实验数据预测的注水百分比的学生化残差超出了
±2 的范围,对应的学生化残差分别为3.724、2.732和-2.155,可判为离群点。为避免过分修剪离群值的数据集,计算出这三个离群点的中心化杠杆值分别为0.1651、0.08888和0.05529,它们是中心化杠杆值的平均值的14.0、7.6及4.7倍,均对回归模型产生强影响。在建立模型时应该将这三组数据从数据集中删除。被剔除的三组异常数据均为14%的注水肉样本,说明在实验过程中可能存在制备14%的注水肉样本时,由于注水百分比较大,发生了少量注入水从肉样本中渗出的现象,导致DA模型在判别10%和14%肉样本时出现错判。![]() 图 6 预测注水百分比的学生化残差的散点图Figure 6. Scatter diagram of student residual of predicted percentage of injected water
图 6 预测注水百分比的学生化残差的散点图Figure 6. Scatter diagram of student residual of predicted percentage of injected water将16个横向弛豫谱参数全部作为自变量进行PLSR建模时,提取三个成分能够累积解释93.71%的因变量的变异信息,但只能累积解释67.4%的自变量集合中的变异信息。增加成分数量对自变量的解释百分比增大,但是,对因变量的解释能力几乎不再提高。作为自变量的横向弛豫谱参数中含有一些难以概括的信息,这些信息对预测注水百分比作用很小。应该对横向弛豫谱参数进行筛选,选出合适的横向弛豫谱参数作为建立模型的自变量。
筛选的原则是既要尽可能不遗漏能对因变量进行重要解释的自变量,又要遵循使自变量的个数尽可能少的原则。在PLSR建模过程中,变量投影重要性分析法是常用的对自变量进行筛选的方法,自变量对因变量的解释能力可以用变量投影重要性指标(VIP)来衡量。自变量对因变量的解释是通过成分来传递的,如果成分对因变量的解释能力很强,而自变量在构造成分时又起到了重要作用,则自变量对因变量的解释能力就强。构成某个成分的自变量的VIP值很大(VIP>1)时,它对因变量的解释能力强。自变量的VIP值很小,则意味着它在解释因变量时起的作用很小,可以直接删除[30]。
图7表示用16个横向弛豫谱参数作为自变量并从中提取三个成分进行PLSR建模时各自变量的VIP值。其中6个参数(S, S23, P23, P22, S22, T22e)的VIP值在三个成分中都超过1,它们对注水百分比的解释能力最强。10个参数(P21, T21e, T23e, T22m,T21m)及(S21, T22b, T23m, T23b, T21b)的VIP值在三个成分中均小于1,表示它们在解释注水百分比时所起的作用较小,可以直接删除。
![]() 图 7 三个成分(1、2和3)中的16个横向弛豫谱参数的VIP值的条形图Figure 7. Bar diagram of the VIP values of the 16 transverse relaxation spectrum parameters corresponding to the three components (1, 2, and 3)
图 7 三个成分(1、2和3)中的16个横向弛豫谱参数的VIP值的条形图Figure 7. Bar diagram of the VIP values of the 16 transverse relaxation spectrum parameters corresponding to the three components (1, 2, and 3)剔除三组异常数据后,校准集由48组数据构成,预测集由34组数据构成。以6个横向弛豫谱参数(S, S23, P23, P22, S22, T22e)作为自变量建立优化的PLSR模型。
图8表示优化PLSR模型对校准集和预测集的预测结果。对决定系数与标准误差计算的结果是Rc2=0.9603,SEC=1.0033%,Rcv2=0.9508,SECV=1.1169%、Rp2=0.9518,SEP=1.1280%。优化PLSR模型的Rc2、Rcv2及Rp2均大于0.95,高于未优化的PLSR模型。表示模型经过优化后,注水百分比解释方差的比率增大,拟合性变得更好。优化的PLSR模型的SEC、SECV以及SEP的值更小,模型的预测精度和稳定性提高。相比末优化的PLSR模型,对预测集样本的预测精度提高了23.4%。在95%的置信概率下,优化后的PLSR模型对预测集样本预测注水比例的置信区间约为2×SEP=2.2560%,优化模型的性能显著提高。该模型不能准确检测小于2.256%的注水百分比,这也可以解释DA模型的一部分错判发生在正常肉和2%的注水肉之间。
![]() 图 8 优化的PLSR模型对校准集和预测集的注水百分比预测的值与实测值的关系Figure 8. The relationship between the predicted value and the measured value of water injection percentage of calibration set and prediction set using the optimized PLSR model
图 8 优化的PLSR模型对校准集和预测集的注水百分比预测的值与实测值的关系Figure 8. The relationship between the predicted value and the measured value of water injection percentage of calibration set and prediction set using the optimized PLSR model3. 结论
采用LF-NMR技术结合判别分析建立注水肉的定性检测模型,通过选择3个区分注水比例能力强且线性相关性较弱的横向弛豫谱参数S、P23、T23e作为预测变量,建立的DA模型是稳定有效的,回代验证和留一交叉验证的总判别正确率分别为89.4%和88.2%。采用LF-NMR技术结合偏最小二乘回归基于全部实验数据、部分实验数据和经过预处理后的实验数据分别建立注水肉的定量检测模型,3种PLSR模型均具有较好的拟合性和稳定性。选择16个横向弛豫谱参数作为自变量进行PLSR建模,基于更多实验样本建立的PLSR模型在性能上表现更优。通过判别和删除3个异常数据,筛选出6个横向弛豫谱参数作为自变量建立的优化PLSR模型,其决定系数Rc2、Rcv2及Rp2均大于0.95,标准误差SEV、SECV及SEP≤1.1280%,在95%的置信概率下,对检测未知样品中注水百分比的置信区间的最好估计值约为2.256%。优化PLSR模型的性能得到了显著改善,预测精度更高,能够对较低注水百分比的注水肉进行快速、无损及有效的定量检测。
-
![]()
图 1 5种不同注水比例的肉样本的横向弛豫谱
Figure 1. Transverse relaxation spectroscopy of five kinds of meat samples with different percentage of injected water
![]()
图 2 对注水比例解释方差的百分比与提取的成分数之间的关系
Figure 2. The relationship between the percentage of explained variance and number of extracted components
![]()
图 3 交叉验证的标准误差与成分数之间的关系
Figure 3. The relationship between SECV and the number of components
![]()
图 4 PLSR模型的校准集样本注水比例的预测值与测量值之间的相关关系
Figure 4. The correlation between the predicted value and the measured value of water injection percentage in the calibration set using PLSR model
![]()
图 5 PLSR模型对校准集和预测集注水百分比进行预测的值与实测值的关系
Figure 5. The relationship between the predicted value and the measured value of water injection percentage of calibration set and prediction set using PLSR model
![]()
图 6 预测注水百分比的学生化残差的散点图
Figure 6. Scatter diagram of student residual of predicted percentage of injected water
![]()
图 7 三个成分(1、2和3)中的16个横向弛豫谱参数的VIP值的条形图
Figure 7. Bar diagram of the VIP values of the 16 transverse relaxation spectrum parameters corresponding to the three components (1, 2, and 3)
![]()
图 8 优化的PLSR模型对校准集和预测集的注水百分比预测的值与实测值的关系
Figure 8. The relationship between the predicted value and the measured value of water injection percentage of calibration set and prediction set using the optimized PLSR model
表 1 类别平均值等同性检验结果
Table 1 Tests of equality of class means
预测变量 Wilks’ Lambda F P S 0.094 192.646 0.000 S23 0.186 87.740 0.000 P23 0.207 76.719 0.000 P22 0.259 57.343 0.000 T23e 0.447 24.765 0.000 T22e 0.517 18.652 0.000 S22 0.583 14.286 0.000 T23m 0.638 11.347 0.000 P21 0.666 10.041 0.000 T21e 0.670 9.843 0.000 T23b 0.776 5.761 0.000 T22m 0.785 5.485 0.001 T21m 0.800 4.997 0.001 T21b 0.844 3.693 0.008 T22b 0.908 2.033 0.098 S21 0.936 1.374 0.250  下载: 导出CSV
下载: 导出CSV
表 2 回代验证与交叉验证的结果
Table 2 Results of two verification methods
验证方法 类别 预测类别的样本数 总数 1 2 3 4 5 回代验证 1 15 2 0 0 0 17 2 3 14 0 0 0 17 3 0 0 17 0 0 17 4 0 0 0 16 1 17 5 0 0 0 3 14 17 交叉验证 1 15 2 0 0 0 17 2 3 14 0 0 0 17 3 0 0 17 0 0 17 4 0 0 0 15 2 17 5 0 0 0 3 14 17
下载: 导出CSV
-
[1] 李欣南, 关一夫. 掺假肉检验技术发展现状[J]. 食品研究与开发,2016,37(5):189−193. doi: 10.3969/j.issn.1005-6521.2016.05.044 [2] 程灵豪, 焦永亮. 白肌肉、注水肉、注胶肉的鉴别检验方法[J]. 中国动物检疫,2015,32(4):28−31. doi: 10.3969/j.issn.1005-944X.2015.04.009 [3] 邓咏梅. 关于我国猪肉水分限量的研究[J]. 肉类工业,2016(11):24−27. doi: 10.3969/j.issn.1008-5467.2016.11.008 [4] 杨志敏, 丁武, 张瑶. 应用近红外技术快速鉴别原料肉注水的研究[J]. 食品研究与开发,2012,33(5):118−120, 128. doi: 10.3969/j.issn.1005-6521.2012.05.034 [5] 孟一, 张玉华, 许丽丹, 等. 近红外光谱技术对猪肉注水、注胶的快速检测[J]. 食品科学,2014,35(8):299−303. doi: 10.7506/spkx1002-6630-201408060 [6] 唐鸣, 田潇瑜, 王旭, 等. 基于近红外特征波段的注水肉识别模型研究[J]. 农业机械学报,2018,49(S1):440−446. doi: 10.6041/j.issn.1000-1298.2018.S0.060 [7] 於海明, 徐佳琪, 刘浩鲁, 等. 基于高光谱和频谱特征的注水肉识别方法[J]. 农业机械学报,2019,50(11):367−372, 366. doi: 10.6041/j.issn.1000-1298.2019.11.041 [8] Kamruzzaman M, Makino Y, Oshita S, et al. Assessment of visible near-infrared hyperspectral imaging as a tool for detection of horsemeat adulteration in minced beef[J]. Food and Bioprocess Technology,2015,8(5):1054−1062. doi: 10.1007/s11947-015-1470-7
[9] 阮榕生. 核磁共振技术在食品和生物体系中的应用[M]. 北京: 中国轻工出版社, 2009: 77−83. [10] Kirtil E, Mecit H, Oztop. 1H Nuclear magnetic resonance relaxometry and magnetic resonance imaging and applications in food science and processing[J]. Food Engineering Reviews,2016,8(1):1−22. doi: 10.1007/s12393-015-9118-y
[11] Wang H, Wang R, Song Y, et al. A fast and non-destructive LF-NMR and MRI method to discriminate adulterated shrimp[J]. Journal of Food Measurement and Characterization,2018,12(2):1340−1349. doi: 10.1007/s11694-018-9748-x
[12] 崔智勇, 丁杰, 徐艳, 等. 基于LF-NMR技术下3种猪肉水分含量预测模型的建立与比较[J]. 食品工业科技,2020,41(5):215−220, 226. [13] 渠琛玲, 汪紫薇, 王雪珂, 等. 基于低场核磁共振的热风干燥过程花生仁含水率预测模型[J]. 农业工程学报,2019,35(12):290−296. doi: 10.11975/j.issn.1002-6819.2019.12.035 [14] Bertram H C, Rasmussen M, Busk H, et al. Changes in porcine muscle water characteristics during growth-an in vitro low-field NMR relaxation study[J]. Journal of Magnetic Resonance,2002,157(2):267−276. doi: 10.1006/jmre.2002.2600
[15] 王胜威, 母应春, 赵旭, 等. 基于LF-NMR弛豫特性对注水、注胶羊肉辨别研究[J]. 食品工业,2015(6):184−188. [16] 王欣, 王志永, 陈利华, 等. 注水肉糜的低场核磁弛豫特性及判别分析[J]. 现代食品科技,2016(5):79−84. [17] 汪冬华. 多元统计分析与SPSS应用(第2版)[M]. 上海: 华东理工大学出版社, 2018: 173−483. [18] Monroy M, Prasher S, Ngadi M O, et al. Pork meat quality classification using Visible/Near-Infrared spectroscopic data[J]. Biosystems Engineering,2010,107 (3):271−276. doi: 10.1016/j.biosystemseng.2010.09.006
[19] Wold S, Sjöström M, Eriksson L. PLS-regression: A basic tool of chemometrics[J]. Chemometrics and Intelligent Laboratory Systems,2001,58(2):109−130. doi: 10.1016/S0169-7439(01)00155-1
[20] Liu J, Cao Y, Wang Q, et al. Rapid and non-destructive identification of water-injected beef samples using multispectral imaging analysis[J]. Food Chemistry,2016,190:938−943. doi: 10.1016/j.foodchem.2015.06.056
[21] ElMasry G, Sun D W, Allen P. Chemical-free assessment and mapping of major constituents in beef using hyperspectral imaging[J]. Journal of Food Engineering,2013,117 (2):235−246. doi: 10.1016/j.jfoodeng.2013.02.016
[22] Hazlewood C F, Chang D C, Nichols B L, et al. Nuclear magnetic resonance transverse relaxation times of water protons in skeletal muscle[J]. Biophysical Journal,1974,14(8):583−606. doi: 10.1016/S0006-3495(74)85937-0
[23] Shaarani S M, Nott K P, Hall L D. Combination of NMR and MRI quantitation of moisture and structure changes for convection cooking of fresh chicken meat[J]. Meat Science,2006,72(3):398−403. doi: 10.1016/j.meatsci.2005.07.017
[24] Fjelkner-Modig S, Tornberg E. Water distribution in porcine M. longissimus dorsi in relation to sensory properties[J]. Meat Science,1986,17(3):213−231. doi: 10.1016/0309-1740(86)90005-7
[25] 谭明乾, 林竹一, 李晨阳, 等. 基于低场核磁共振技术的小鼠体成分无损分析方法开发[J]. 分析科学学报,2018,34(4):24−31. [26] Kelly J F D, Downey G, Fouratier V. Initial study of honey adulteration by sugar solutions using midinfrared (MIR) spectroscopy and chemometrics[J]. Journal of Agricultural and Food Chemistry,2004,52(1):33−9. doi: 10.1021/jf034985q
[27] 闵顺耕, 李宁, 张明祥. 近红外光谱分析中异常值的判别与定量模型优化[J]. 光谱学与光谱分析,2004(10):1205−1209. doi: 10.3321/j.issn:1000-0593.2004.10.014 [28] Nicola B M, Beullens K, Bobelyn E, et al. Nondestructive measurement of fruit and vegetable quality by means of NIR spectroscopy: A review[J]. Postharvest Biology & Technology,2007,46(2):99−118.
[29] Samuel D, Park B, Sohn M, et al. Visible-near-infrared spectroscopy to predict water-holding capacity in normal and pale broiler breast meat[J]. Poultry Science,2011,90 (4):914−921. doi: 10.3382/ps.2010-01116
[30] 张恒喜. 小样本多元数据分析方法及应用[M]. 西安: 西北工业大学出版社, 2002.







 下载:
下载:
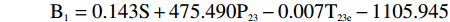
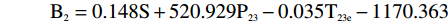
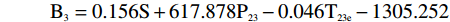
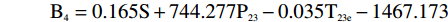


















计量
- 文章访问数: 231
- HTML全文浏览量: 64
- PDF下载量: 17



