


An Anthocyanin Prediction Model of Blueberry Pomace Based on Stacked Supervised Autoencoders
-
摘要: 基于可见近红外光谱技术,采用深度学习中的堆叠监督自编码器(stacked supervised autoencoders,SSAE)对蓝莓果渣的花青素含量进行了建模。首先对光谱数据进行预处理和特征筛选处理,以预设SSAE模型的预测集均方根误差(RMSEP)最低为标准,选择出178个特征波长;以选择出的特征波长处的吸光值作为SSAE模型的输入,以蓝莓果渣中的花青素含量为输出,讨论SSAE模型激活参数、节点数、训练次数和学习率,得到SSAE最优参数,即激活函数rule、结构178-60-5-1、训练次数70、学习率0.01。选取训练集均方根误差(RMSEC)、预测集均方根误差(RMSEP)、预测集相关系数(Rp)为评价标准,获得所建立模型的RMSEC、RMSEP、Rp分别为1.0500、0.3835、0.9042。最后通过与经典回归预测模型极限学习机(extreme learning machine,ELM)、最小二乘支持向量机回归(least squares support vector regression,LSSVR)和偏最小二乘回归(partial least squares regression,PLSR)算法进行对比,发现本研究所建SSAE模型的预测精度更高,表明SSAE模型与可见近红外光谱结合能有效预测蓝莓果渣中的花青素含量。Abstract: Based on the visible and near-infrared reflectance spectroscopy technique, stacked supervised autoencoders (SSAE) in deep learning were used to model the anthocyanin content of blueberry pomace. First, preprocessing and feature screening for spectral data were performed. With the minimum value of prediction set root mean square error (RMSEP) of the preset SSAE model as the standard, 178 characteristic wavelengths were selected. The absorbance of the selected characteristic wavelength was used as the input to the SSAE model. The anthocyanin content of blueberry pomace was used as the output. By exploring the activation parameters, node number, training times and learning rate of the SSAE model, the optimal parameters of SSAE were obtained, namely, the activation function of rule, the structure of 178-60-5-1, the training times of 70, and the learning rate of 0.01. The training set root mean square error (RMSEC), prediction set root mean square error (RMSEP), and prediction set correlation coefficient (Rp) were selected as the evaluation criteria. The RMSEC, RMSEP, and Rp of the established model were 1.0500, 0.3835, and 0.9042, respectively. Compared with the classic regression prediction model extreme learning machine (ELM), least squares support vector regression (LSSVR) and partial least squares regression (PLSR) algorithm, the prediction accuracy of the SSAE model was higher. Therefore, the combination of the SSAE model with visible and near-infrared reflectance spectroscopy proved to be effective in predicting anthocyanin content of blueberry pomace.
-
蓝莓中富含多种对人体有益的营养成分,其中包括花青素、鞣花酸和紫檀芪等,具有抗氧化、消炎、调节免疫力等功效,被人称为浆果之王。蓝莓不易保存及运输,因此蓝莓果汁产业发展迅速,而蓝莓果渣作为蓝莓果汁产业的副产品,功能性成分残留率也较高,尤其是花青素,其含量约为果汁中的花青素含量的5倍左右[1-4]。当蓝莓果渣中花青素含量较高时,可用于制作保健品,提高自身免疫力,另外其花青素含量较低时也可将蓝莓果渣粉末加入曲奇面粉中提高曲奇中的酚类化合物和膳食纤维矿物质的含量。目前市场对于蓝莓果渣的开发还属于初级阶段,为了充分开发蓝莓资源,推进发展蓝莓副产品,针对蓝莓果渣中花青素含量的测定更具有实际意义。
可见近红外光谱技术作为一种低成本、零污染、分析速度快的检测技术,已在国内外得到了大量的应用,水果领域的研究主要在于利用近红外光谱快速测定西瓜、葡萄、苹果、草莓、猕猴桃[5-9]等糖度和可溶性固形物等主要成分含量,在蓝莓方面的研究主要集中在蓝莓的鲜果方面,常研究的指标包括花青素[10]、总酚[10]、可溶性固形物[11]、硬度[12]等。目前针对蓝莓果渣的研究也逐渐得到重视,张丽娟等[13]通过使用近红外光谱法结合竞争自适应重加权采样(competitive adaptive reweighted sampling,CARS)和偏最小二乘法回归(partial least squares regression,PLSR)对不同品种果渣中的花色苷含量进行测定,得到RMSEP为1.0049、R2p达到0.8857,表明近红外光谱对蓝莓果渣营养成分含量测定的具有可行性,但这方面的研究成果还相对较少。
深度学习因其在众多有监督学习问题上的优势,已引起了学者们的关注。目前,将深度学习与近红外光谱技术的融合[14-17]也逐渐活跃,彭发等[7]将近红外光谱技术与深度学习相结合,建立了苹果的深度学习糖度预测模型,在大批量样本上获得了较好效果,但对于小样本而言,其所建立的MobileNetV2糖度预测模型的预测结果相较于传统机器学习模型较差。
堆叠监督自编码器(stacked supervised autoencoders,SSAE)[18]是深度学习算法的一种,可以通过有监督的非线性运算无限接近预测值,在处理大量数据的同时有效避免陷入局部最优。SSAE中监督自编码器(supervised autoencoders,SAE)[19]的监督机制可以在理化值为参考下提取到与理化值高度相关的特征并建立预测模型。在SSAE中采用有监督的预训练参数以及梯度下降法也可以更好的避免模型出现梯度消失和局部最优问题。SSAE相较于传统线性模型可以深度探究变量间的关系,并且相较于传统非线性模型也可以避免出现局部最优以及过拟合问题。
鉴于此,本研究采用近红外光谱技术和深度学习对蓝莓果渣中的花青素含量进行定量检测研究。首先,对近红外光谱数据进行数据预处理和特征筛选讨论,以深度学习模型训练结果确定最优的数据预处理和特征筛选方案;之后对深度学习模型参数进一步讨论,确定最佳预测模型参数,同时得到最优预测结果。为了检验堆叠监督自编码器模型的优越性,与经典预测模型进行对比,旨在为蓝莓果渣的快速检测及分级提供参考方案。
1. 材料与方法
1.1 材料与仪器
蓝莓 品种为兔眼,选取成熟果实作为实验样本,采购于辽宁丹东生产基地。对常温状态下的蓝莓样品进行榨汁并过滤,得到蓝莓鲜果渣,之后将蓝莓鲜果渣放入恒温干燥箱中于40 ℃烘干,待样品冷却后再利用高速粉碎机进行粉碎处理,后过20目筛,得到蓝莓果渣干粉末样品。将每种蓝莓果渣样品进行随机划分,以每3 g为一组,总共150组样本;纤维素酶 40000 U/g,山东隆科特酶制剂有限公司;矢车菊素-3-O-葡萄糖苷对照品 河南标准物质研发中心。
LabSpec 5000光谱仪 美国ASD公司;UV-1801紫外可见分光光度计 北京北分瑞利分析仪器(集团)有限责任公司;TD6离心机 长沙湘智离心机仪器有限公司;LT202C电子天平 常熟市天量仪器有限责任公司;高速粉碎机 天津市泰斯特仪器有限公司;旋钮超声波清洗器KS-2200B 昆山洁力美超声仪器有限公司。
1.2 实验方法
1.2.1 果渣花青素含量的测定
蓝莓花青素的提取方法参照赵尔丰等[20]的方法,取蓝莓果渣1 g加入10 mL水中进行匀浆,匀浆后加入5 mg纤维素酶,在温度为50 ℃、超声波功率为200 W的条件下超声提取10 min,之后利用95%食用酒精7 mL进行强化提取(提取条件同上一步相同),将得到的提取液放入离心机中离心10 min(4000 r/min),取上清液1 mL分别加入pH1.0和pH4.5溶液进行缓冲并定容至10 mL,利用紫外分光光度计UV-1801测定每个样品在两种不同pH溶液中于520和700 nm处的吸光值,此时选取的比色皿光程为1 cm,最终吸光度A为:
A=(Aa1−Ab1)−(Aa2−Ab2) (1) 式中:Aa1、Aa2为样品分别在pH1.0和pH4.5溶液中于520 nm处的吸光值;Ab1、Ab2为样品分别在pH1.0和pH4.5溶液中于700 nm处的吸光值。进而求得每组果渣样品中的花青素浓度C [21] :
C(mg⋅L−1)=A/ε×L×103×MW×稀释倍数 (2) 式中:MW为摩尔质量;ε为摩尔吸光系数;L为比色皿光程(cm)。摩尔质量和摩尔吸收系数均以蓝莓果渣中主要花青素之一的矢车菊素-3-O-葡萄糖苷(Cyanidin-3-O-glucoside)进行计算。
1.2.2 近红外光谱的采集
取每个样品蓝莓果渣2.5 g装填于光程为1 cm的比色皿中压平并保持厚度为3 cm,将样品池放入不透光的黑盒中,使用近红外光谱仪对样品进行350~2500 nm的近红外漫反射光谱采样,扫描次数32,采集间隔1 nm。对每组蓝莓果渣样品扫描三次,将三次扫描光谱均值作为每组样品的光谱。
1.2.3 样本集划分
选取隔三选一法进行样本集划分,将花青素含量Y值进行由大到小排序,每间隔三个Y值选取一个样本作为测试集,其余用作训练集,其中,Y值的最大值和最小值应在训练集中。得到本研究的训练集:测试集为3:1,即训练集中的样品数为120个,测试集中的样品数有30个。
1.3 预处理和特征筛选方法
1.3.1 预处理方法
本研究讨论不同预处理对模型的影响,旨在寻找最优模型。采用常用的预处理方法[22]卷积滤波平滑处理(Savitzky-Golay smoothing,SG)、多元散射校正(multiplicative scatter correction,MSC)、标准正态变换(standard normal variate,SNV)、一阶导数(1st-D)、去趋势矫正(detrend correction,DT)进行讨论研究。
1.3.2 特征筛选方法
本研究选用Pearson相关性分析和CARS两种特征筛选方法,以SSAE模型的预测结果RMSEP最低为依据,确定适用于本研究的最佳特征筛选方法。对401~2400 nm范围的光谱数据采用SG、MSC、SNV、1st-D、DT进行预处理,以上预处理方法均使用The Unscrambler X 10.4软件进行。
Pearson相关性分析[23]是指对两个及以上的相关变量之间进行分析,从而衡量两个变量间的相关程度。本研究采用Pearson相关性分析,利用Pearson相关性分析对蓝莓果渣理化值和不同波长下的吸光值进行分析,首先选取显著性水平P值小于0.001的波长,之后根据皮尔逊系数由大到小排列。
CARS是通过自适应重加权采样(adaptive reweighted sampling,ARS)技术选择出PLS模型中回归系数绝对值大的波长点,去掉权重小的波长点,利用交互验证选出RMSECV指最低的子集,可有效寻出最优变量组合。
1.4 SSAE算法设计和参数选择
1.4.1 SSAE算法
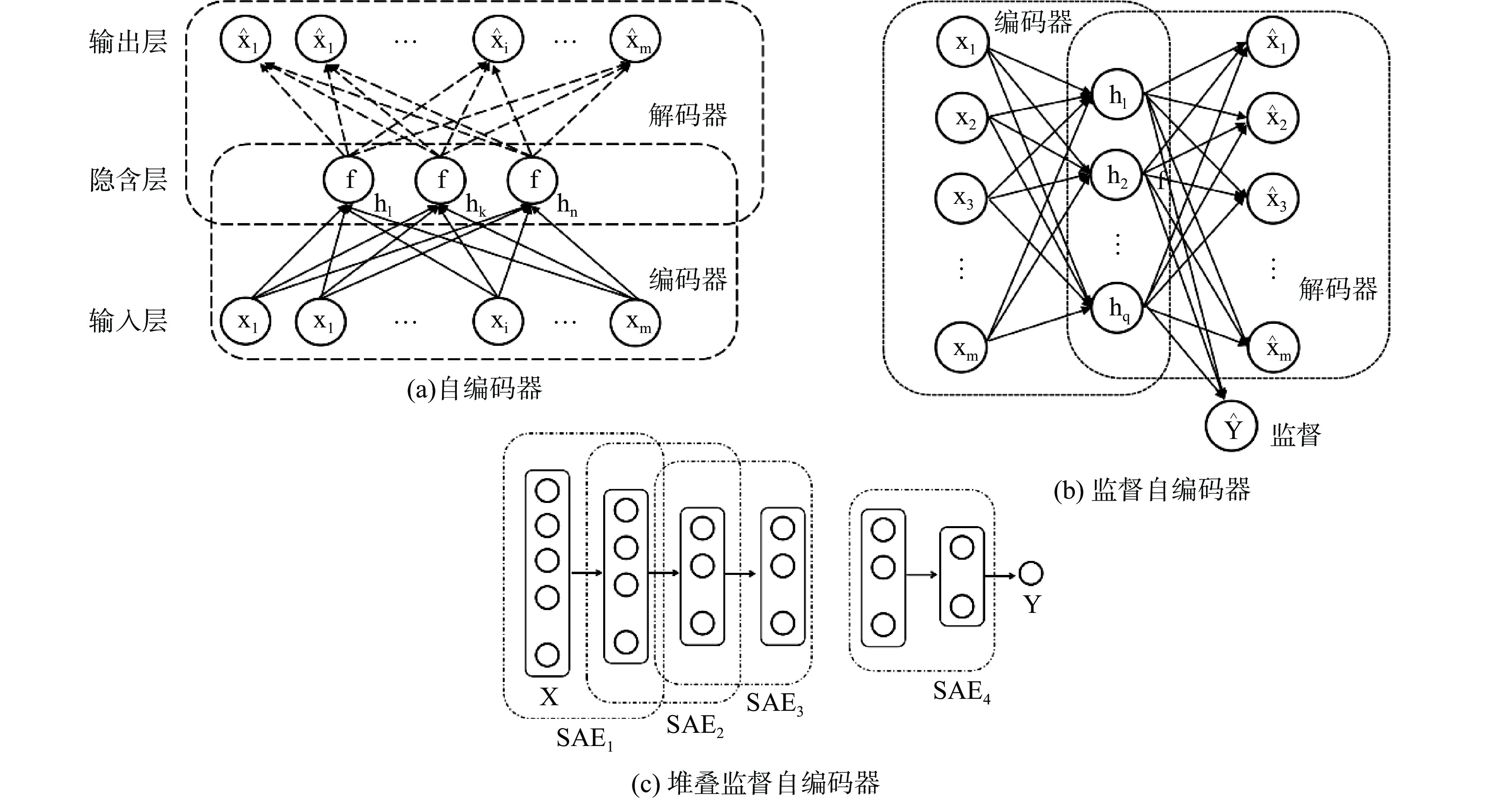
堆叠监督自编码器是在引入监督机制的自编码器基础上通过堆叠得到的。在自编码中引入监督机制,使得自编码器可以提取到与理化值高度相关的特征。其中单个的监督自编码器是一个浅层的神经网络,能提取到的特征十分有限,因此对监督自编码器进行堆叠,就可以提取到更深层次的特征。SSAE是一种深度神经网络,通过非线性运算达到降维的目的。
图1(a)~图1(c)分别为自编码器、监督自编码和堆叠监督自编码器的结构图。自编码器是由输入层、隐含层、输出层组成,其中包含一个编码器和一个解码器。监督自编码器比自编码器多了一个与隐含层全连接的监督层,监督层的主要目的是通过减小重构误差和预测误差,达到降维和准确预测的目的。堆叠监督自编码器拥有更深的网络结构,可以在高维数据中学习到更深的特征表示。
1.4.2 监督机制的激活函数和损失函数
在SSAE中,假定隐含层与监督层的关系表达式为
ˆy=P(Wph+bp) ,其中ˆy 为监督层的输出,Wp为权重矩阵,bp为偏置向量,P为激活函数。回归问题中常用的激活函数为rule,tanh。本研究主要讨论不添加激活函数即f(x)=x及分别添加激活函数tanh、rule这三种激活模式对模型的影响,以此确定最佳模型。SSAE算法中的损失函数[7]为
Loss=λLossx+(1−λ)Lossy ,是重构误差Lossx 和预测误差Lossy 的加权和。1.4.3 隐含层层数和节点数
本研究采用经典四层隐含层模型,输入层为经过预处理和特征筛后的数据,输出层为预测值,以输入层的数据维数和输出层的预测值1维为参考标准,对隐含层节点数进行讨论。
1.4.4 训练次数和学习率
训练次数和学习率一直是模型的重要参数,本研究在SSAE模型训练时的训练次数拟分别取值为60、70、80、90,进而利用梯度下降法寻找最优值,其中学习速率取值分别为0.1、0.01、0.001。
1.5 评价指标
为评价模型预测的准确性,本研究采用均方根误差RMSE和决定系数R两个评价指标,其计算公式分别如式(3)、(4)。RMSE用来衡量预测值和真实值之间的标准误差,标准误差越低,表示模型精度越高。R用来衡量模型对数据的拟合能力,越接近于1,表示模型对数据的拟合越好,反之越接近0,表示拟合较差。
RMSE=√1mm∑i=1(yi−^yi)2 (3) R=√1−(∑i(ˆyi−yi)2)/m(∑i(¯yi−yi)2)/m (4) 式中:
^yi 为光谱预测值;yi 为实际值;¯yi 为实际值的平均值;m为样品数。2. 结果与分析
2.1 特征筛选
2.1.1 蓝莓果渣光谱数据特征初筛
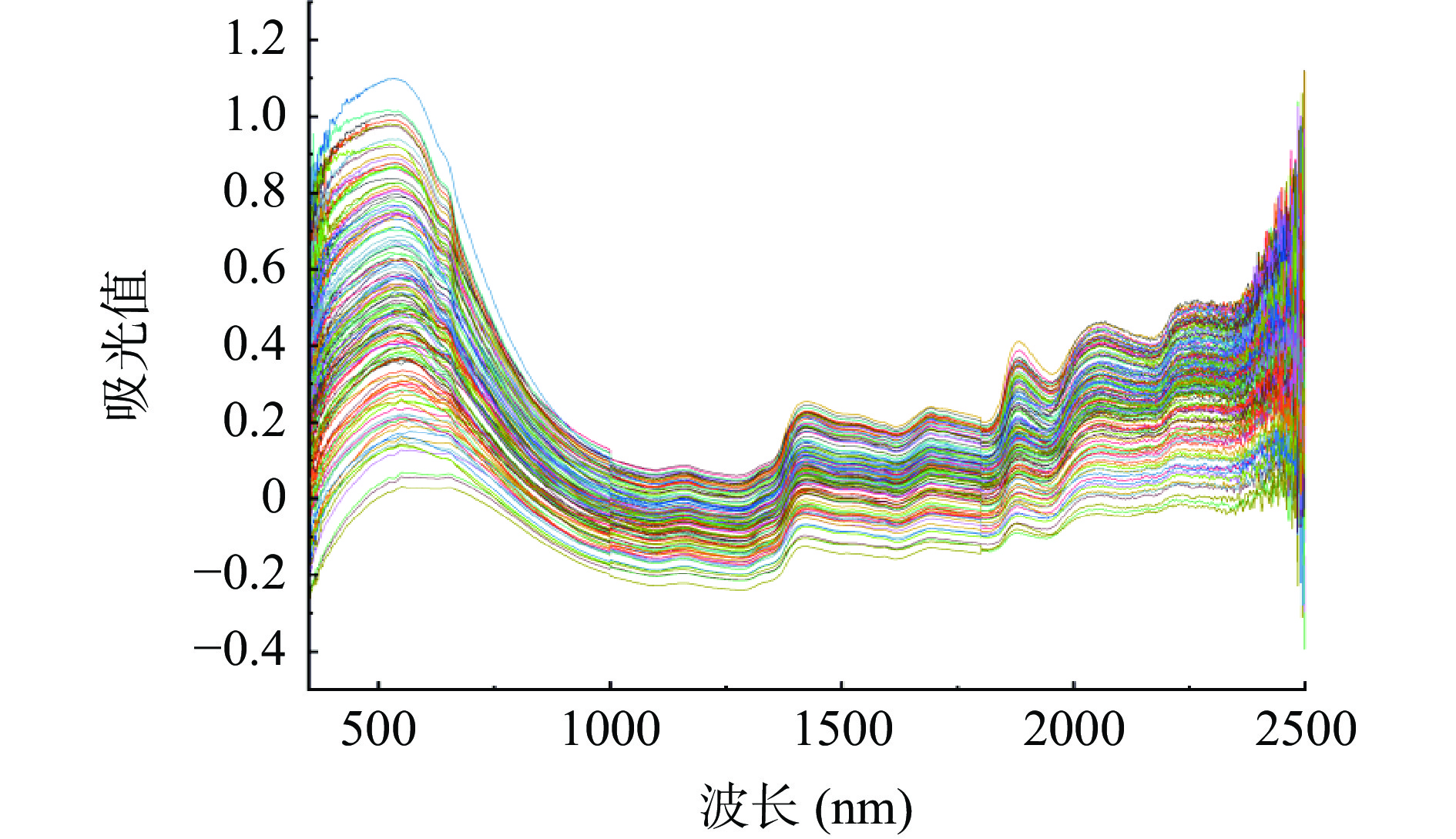
本研究采用LabSpec 5000光谱仪获得的光谱数据范围为350~2500 nm,图2显示了蓝莓果渣350~2500 nm的原始光谱图。观察图2,发现两端光谱数据存在明显噪声,因此,本研究选用波段范围为401~2400 nm的数据进行研究。
从图2中可以看出,在波长590、1450、1720、1900和2080 nm附近有明显的吸收峰,并且波峰处的吸光值也有明显不同,近红外光谱反映的是含氢基团X-H(X=C、N、O)振动的倍频和合频吸收,而蓝莓果渣中的花青素有机物含有各种含氢基团,故近红外光谱可以用来构建蓝莓果渣花青素的定量模型。由于蓝莓果渣含有多种有机成分并且近红外光谱的吸收带较宽,各成分之间的光谱吸收带具有高度重叠性,因此无法仅依据近红外光谱确定吸收峰处对应的具体官能团及物质。
2.1.2 蓝莓果渣光谱数据特征最优值确定
选取原始数据和分别进行SG、MSC、SNV、1st-D、DT预处理情况下的数据以及分别经过Pearson相关性分析和CARS降维后的数据,其中Pearson相关性分析选取未进行预处理及分别进行SG、MSC、SNV、1st-D、DT预处理下的皮尔逊系数分别为0.834、0.835、0.766、0.769、0.612、0.620得到特征维数分别为178、166、123、92、144、186。而CARS选取在未进行预处理及分别进行SG、MSC、SNV、1st-D、DT预处理下的数据特征维数分别为54、113、85、136、65、103。将以上数据分别输入SSAE模型中,得到不同预处理方法和特征筛选方式下的SSAE模型的预测结果,如表1所示。此时SSAE模型参数为:激活函数为relu,隐含层节点数为(30,5),训练次数为70,学习率为0.01。
表 1 不同预处理和特征选择方式下SSAE模型结果Table 1. SSAE model results under different preprocessing and feature selection methods预处理方式 特征选择方式 RMSEC RMSEP Rp SG CARS 4.6994 0.6466 0.6940 Pearson 1.1321 0.4435 0.8696 不使用降维 1.8665 0.4302 0.8778 MSC CARS 1.5124 0.6942 0.6344 Pearson 1.7429 0.7063 0.6177 不使用降维 1.7991 0.6540 0.6854 SNV CARS 5.1595 0.6002 0.7439 Pearson 5.2719 0.6342 0.7081 不使用降维 5.8429 0.6692 0.6669 1st-D CARS 1.4947 0.8981 0.0088 Pearson 0.9399 0.8980 0.0148 不使用降维 1.1199 0.8982 0.0088 DT CARS 1.4034 0.7954 0.4645 Pearson 1.8946 0.6792 0.6543 不使用降维 1.6619 0.5357 0.8027 源数据 CARS 1.5709 0.4717 0.8510 Pearson 1.1095 0.4154 0.8866 不使用降维 2.0287 0.4267 0.8799 由表1可以看出,利用CARS进行数据降维时,每一种预处理方法的结果排序为:源数据>SNV>SG>MSC>DT>1st-D,在采用Pearson相关性对数据进行降维时,结果表现排序为:源数据>SG>SNV>DT>MSC>1st-D,在不利用任何降维方法时,数据表现排序为:源数据>SG>DT>MSC>SNV>1st-D。综合三组排序结果可以看到,不采用任何预处理的源数据均为每组降维结果的最优。其中利用CARS降维的源数据得到的RMSEP为0.4717,Rp为0.8510,采用Pearson相关关系时得到的RMSEP为0.4154,Rp为0.8866,不采用特征筛选的数据得到的RMSEP为0.4267,Rp为0.8799,可见,利用SSAE模型进行预测时特征筛选结果排序为:Pearson>不使用降维>CARS。因此,本研究采用源数据经Pearson降维后的178维数据即特征数据作为后续模型的输入。
2.2 SSAE算法的优化结果
2.2.1 激活函数确定
激活函数是在人工神经网络模型中插入的一个函数,用来进行较为复杂的非线性特征学习,使得模型可以学习到更加复杂的特征。本研究中探讨未使用激活函数即f(x)=x,分别使用激活函数relu和激活函数tanh对预测模型的影响,通过训练获得三种激活模式的结果如表2所示。
表 2 不同激活函数下SSAE模型结果Table 2. SSAE model results under different activation functions激活函数 RMSEC RMSEP Rp tanh 1.0191 0.4814 0.8442 rule 1.1095 0.4154 0.8866 未使用激活函数 0.8755 0.4493 0.8659 由表2可以看出,三种激活模式中,使用激活函数rule的RMSEP为0.4154,Rp为0.8866,优于未使用激活函数的0.4493和0.8659,同样优于使用激活函数tanh的0.4814和0.8442,因此本研究选取rule为激活函数用于后续研究。
2.2.2 隐含层节点数的确定
由于本研究的输入数据为178维,维数较低,因此选取四层神经网络结构,以不同神经元配置获得的SSAE模型预测结果,讨论隐含层中神经元个数的不同配置对模型的影响。此时模型的训练结果如表3所示。
表 3 不同神经元配置的SSAE建模结果Table 3. SSAE modeling results for different neuron configurations神经元配置 RMSEC RMSEP Rp (90,30) 0.9451 0.4155 0.8866 (90,15) 1.0142 0.3929 0.8992 (90,10) 1.0493 0.3852 0.9034 (60,30) 0.9890 0.4240 0.8816 (60,15) 1.0980 0.4107 0.8893 (60,10) 1.1207 0.3915 0.9000 (60,5) 1.0500 0.3835 0.9042 (30,15) 1.1805 0.4162 0.8861 (30,10) 1.2605 0.4403 0.8716 (30,5) 1.1095 0.4154 0.8866 由表3可知,当隐含层神经元为(60,5)时,RMSEP最小,为0.3835,Rp也最大,为0.9042,因此确定本研究的SSAE模型网络结构为178-60-5-1。
2.2.3 训练次数和学习率确定
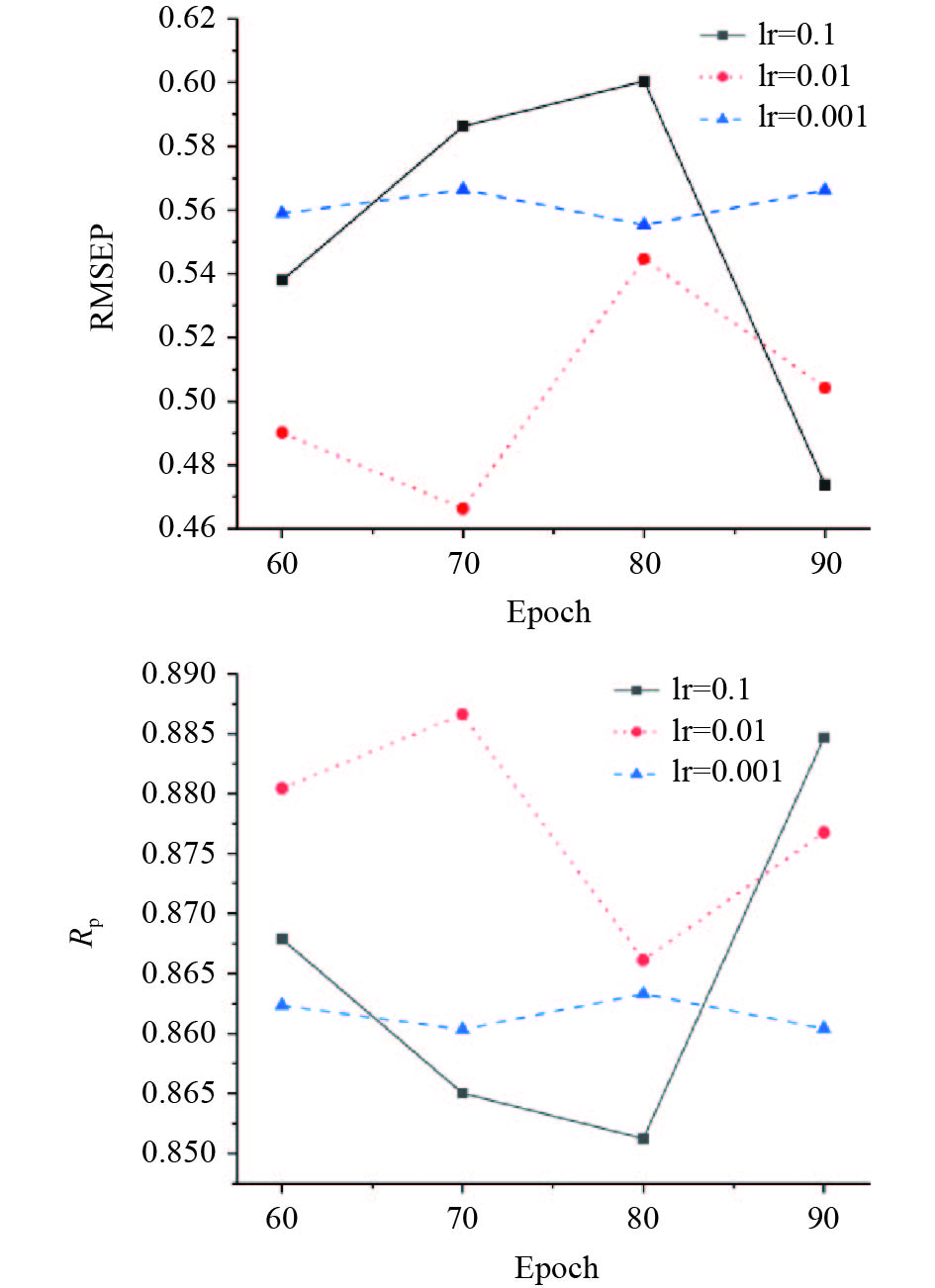
在训练过程中,学习率和训练次数对模型来说有着重要的影响,学习率过大,模型不容易达到最优,过小,又会导致过拟合。训练次数的多少也同样会对模型拟合有着很大的影响。本研究对模型的学习率和训练次数进行了讨论,训练结果如图3所示。
![]() 图 3 不同训练次数和学习率对模型的影响注:(a)不同训练次数和学习率对RMSEP的影响;(b)不同训练次数和学习率对Rp的影响。Figure 3. Effect of different training times and learning rates on the model
图 3 不同训练次数和学习率对模型的影响注:(a)不同训练次数和学习率对RMSEP的影响;(b)不同训练次数和学习率对Rp的影响。Figure 3. Effect of different training times and learning rates on the model图3中可以看到,整体上当训练次数在60~80范围内时,学习率lr=0.01的RMSEP始终优于lr=0.001和lr=0.1,并在epoch=70时,达到最优;但在训练次数epoch=90时,lr=0.1却优于lr=0.01和lr=0.001。比较当epoch=70和epoch=90时,epoch=70的RMSEP值低于epoch=90,Rp值高于epoch=90,因此本研究采用epoch=70,lr=0.01作为最终研究参数。
2.3 SSAE算法的最优预测结果及模型对比
为验证本文所用SSAE算法建立蓝莓果渣中花青素预测模型的有效性,将建模结果与传统方法进行了比较。在最优条件下,即数据维数为178维,激活函数为relu,网络结构为178-60-5-1,训练次数为70,学习率为0.01,获得SSAE模型的预测结果,得到RMSEP为0.3835,Rp为0.9042。
分别采用经典回归模型ELM[24]、LSSVR[25]和PLSR建立预测模型,并对模型ELM、LSSVR和PLSR分别进行预处理和特征筛选讨论,建立最佳模型。ELM模型经过预处理和特征筛选研究后确定,当预处理为SG并且不进行特征筛选时,模型达到最优,得到RMSEP为0.4025,Rp为0.8916;对LSSVR进行相同的研究后得到,当不进行预处理仅进行Pearson特征筛选的178维数据时结果最优,获得RMSEP为0.4479,Rp为0.8746。研究PLSR时,发现当预处理为一阶导数(1st-D)并且以CARS作为特征筛选后的136维预测结果最优,得到RMSEP为0.4012,Rp为0.8939,结果整理如表4所示。
表 4 不同模型的建模预测结果Table 4. Modeling prediction results of different models模型 输入模型的数据维数 RMSEP Rp O+Pearson+SSAE 178 0.3835 0.9042 SG+O+ELM 2000 0.4025 0.8916 O+Pearson+LSSVR 178 0.4479 0.8746 1st-D+CARS+PLSR 136 0.4012 0.8939 注:表中的O代表不进行预处理或特征筛选。 从表4中可以看出,以SSAE模型进行预测时,发现原始数据利用Pearson相关性分析进行特征筛选时的结果最优,RMSEP为0.3835,Rp为0.9042;而在选用CARS作为特征选择方法时对通过一阶导数处理后的数据进行特征筛选并利用PLSR进行预测的结果也较优,达到RMSEP为0.4012,Rp为0.8939。以预测结果对各模型进行排序,结果为O+Pearson+SSAE>1st-D+CARS+PLSR>SG+O+ELM>O+Pearson+LSSVR。可见,本研究提出的SSAE模型取得了最佳的预测结果。
3. 结论
本研究基于可见近红外光谱对蓝莓果渣中的花青素含量进行了预测研究,利用堆叠监督自编码器进行建模,采用原始数据和SG、MSC、SNV、1st-D、DT五种预处理方法以及不进行降维和CARS、Pearson两种降维方法对光谱数据进行处理,得到本模型最佳的预处理和特征提取方法为不进行预处理+Pearson相关性分析,提取到的特征为178维,仅占源始数据的8.9%,大大精简了模型,此时模型的预测结果为RMSEC、RMSEP和Rp分别为:1.2837、0.4233、0.8820。将经过预处理和特征筛选的光谱数据作为SSAE模型的输入,以果渣样品中的花青素含量为输出,对SSAE模型进行激活函数、神经元配置的设计、训练次数和学习率的讨论,确定SSAE模型的最优参数为:激活函数为rule、网络结构为178-60-5-1、学习率为0.01、训练次数为70次,得到结果RMSEC、RMSEP和Rp分别为:1.0500、0.3835、0.9042,最后与ELM、LSSVR、PLSR模型进行比较,结果表明,本研究建立的SSAE模型达到最优,SSAE模型预测结果的RMSEP与ELM、LSSVR、PLSR模型相比分别降低了4.7%、14.8%、4.4%,Rp分别提高了1.2%、3.4%、1.2%,具有较好的预测结果,表明SSAE模型能有效预测蓝莓果渣中的花青素含量,同时表明了SSAE与可见近红外光谱结合拥有较大潜力。
-
![]()
图 3 不同训练次数和学习率对模型的影响
注:(a)不同训练次数和学习率对RMSEP的影响;(b)不同训练次数和学习率对Rp的影响。
Figure 3. Effect of different training times and learning rates on the model
表 1 不同预处理和特征选择方式下SSAE模型结果
Table 1 SSAE model results under different preprocessing and feature selection methods
预处理方式 特征选择方式 RMSEC RMSEP Rp SG CARS 4.6994 0.6466 0.6940 Pearson 1.1321 0.4435 0.8696 不使用降维 1.8665 0.4302 0.8778 MSC CARS 1.5124 0.6942 0.6344 Pearson 1.7429 0.7063 0.6177 不使用降维 1.7991 0.6540 0.6854 SNV CARS 5.1595 0.6002 0.7439 Pearson 5.2719 0.6342 0.7081 不使用降维 5.8429 0.6692 0.6669 1st-D CARS 1.4947 0.8981 0.0088 Pearson 0.9399 0.8980 0.0148 不使用降维 1.1199 0.8982 0.0088 DT CARS 1.4034 0.7954 0.4645 Pearson 1.8946 0.6792 0.6543 不使用降维 1.6619 0.5357 0.8027 源数据 CARS 1.5709 0.4717 0.8510 Pearson 1.1095 0.4154 0.8866 不使用降维 2.0287 0.4267 0.8799  下载: 导出CSV
下载: 导出CSV
表 2 不同激活函数下SSAE模型结果
Table 2 SSAE model results under different activation functions
激活函数 RMSEC RMSEP Rp tanh 1.0191 0.4814 0.8442 rule 1.1095 0.4154 0.8866 未使用激活函数 0.8755 0.4493 0.8659
下载: 导出CSV
表 3 不同神经元配置的SSAE建模结果
Table 3 SSAE modeling results for different neuron configurations
神经元配置 RMSEC RMSEP Rp (90,30) 0.9451 0.4155 0.8866 (90,15) 1.0142 0.3929 0.8992 (90,10) 1.0493 0.3852 0.9034 (60,30) 0.9890 0.4240 0.8816 (60,15) 1.0980 0.4107 0.8893 (60,10) 1.1207 0.3915 0.9000 (60,5) 1.0500 0.3835 0.9042 (30,15) 1.1805 0.4162 0.8861 (30,10) 1.2605 0.4403 0.8716 (30,5) 1.1095 0.4154 0.8866
下载: 导出CSV
表 4 不同模型的建模预测结果
Table 4 Modeling prediction results of different models
模型 输入模型的数据维数 RMSEP Rp O+Pearson+SSAE 178 0.3835 0.9042 SG+O+ELM 2000 0.4025 0.8916 O+Pearson+LSSVR 178 0.4479 0.8746 1st-D+CARS+PLSR 136 0.4012 0.8939 注:表中的O代表不进行预处理或特征筛选。
下载: 导出CSV
-
[1] 高明明, 肖月欢, 王幸, 等. 我国蓝莓食品加工现状分析[J]. 保鲜与加工,2017,17(3):111−117. [GAO Mingming, XIAO Yuehuan, WANG Xing, et al. Analysis on the status quo of blueberry food processing in my country[J]. Storage and Process,2017,17(3):111−117. doi: 10.3969/j.issn.1009-6221.2017.03.021 [2] 张昌容, 李志, 何永福, 等. 蓝莓果渣主要功能性成分及综合利用研究进展[J]. 食品科技,2021,46(6):110−111. [ZHANG Changrong, LI Zhi, HE Yongzhi, et al. Research progress on main functional components and comprehensive utilization of blueberry pomace[J]. Food Science and Technology,2021,46(6):110−111. doi: 10.13684/j.cnki.spkj.2021.06.019 [3] 韩鹏祥, 张蓓, 冯叙桥, 等. 蓝莓的营养保健功能及其开发利用[J]. 食品工业科技,2015,36(6):370−375,379. [HAN Pengxiang, ZHANG Pei, FENG Xuqiao, et al. Nutrition and health care function of blueberry and its development and utilization[J]. Science and Technology of Food Industry,2015,36(6):370−375,379. [4] 雷良波, 杨浩, 陈军李, 等. 蓝莓果渣开发利用研究进展[J]. 中国酿造,2017,36(10):17−22. [LEI Liangbo, YANG Hao, CHEN Junjie, et al. Research progress on development and utilization of blueberry pomace[J]. China Brewing,2017,36(10):17−22. doi: 10.11882/j.issn.0254-5071.2017.10.005 [5] JIE D F, XIE L J, FU X P, et al. Variable selection for partial least squares analysis of soluble solids content in watermelon using near-infrared diffuse transmission technique[J]. Journal of Food Engineering,2013,118(4):387−392. doi: 10.1016/j.jfoodeng.2013.04.027
[6] JUAN F, TERESA G, JAVIER T, et al. Assessment of amino acids and total soluble solids in intact grape berries using contactless Vis and NIR spectroscopy during ripening[J]. Talanta,2019,199:244−253. doi: 10.1016/j.talanta.2019.02.037
[7] 彭发, 王震, 刘双喜, 等. 基于偏最小二乘法和深度学习的近红外糖度预测[J]. 吉林农业大学学报,2021,43(2):196−204. [PENG Fa, WANG Zhen, LIU Shuangxi, et al. Near-infrared sugar content prediction based on partial least squares and deep learning[J]. Journal of Jilin Agricultural University,2021,43(2):196−204. doi: 10.13327/j.jjlau.2021.6116 [8] 张娟, 原帅, 张骏. 基于小波变换-遗传算法-偏最小二乘的草莓糖度检测研究[J]. 分析科学学报,2020,36(1):111−115. [ZHANG Juan, YUAN Shuai, ZHANG Jun. Research on brix detection of strawberry based on wavelet transform-genetic algorithm-partial least square[J]. Journal of Analytical Science,2020,36(1):111−115. [9] ALI M T, ABBAS A, NILOOFAR L N. Prediction of kiwifruit firmness using fruit mineral nutrient concentration by artificial neural network (ANN) and multiple linear regressions (MLR)[J]. Journal of Integrative Agriculture,2017,16(7):1634−1644. doi: 10.1016/S2095-3119(16)61546-0
[10] 刘小路, 薛璐, 鲁晓翔, 等. 近红外光谱技术快速无损检测蓝莓总黄酮、花青素的研究[J]. 食品工业科技,2015,36(16):58−61, 67. [LIU Xiaolu, XUE Lu, LU Xiaoxiang, et al. Research on rapid non-destructive detection of total flavonoids and anthocyanins in blueberry by near-infrared spectroscopy[J]. Science and Technology of Food Industry,2015,36(16):58−61, 67. [11] ZHENG W, BAI Y H, LUO H, et al. Self-adaptive models for predicting soluble solid content of blueberries with biological variability by using near-infrared spectroscopy and chemometrics[J]. Postharvest Biology and Technology,2020,169:111286. doi: 10.1016/j.postharvbio.2020.111286
[12] 薛璐, 刘小路, 鲁晓翔, 等. 近红外漫反射无损检测蓝莓硬度的研究[J]. 浙江农业学报,2015,27(9):1646−1651. [XUE Lu, LIU Xiaolu, LU Xiaoxiang, et al. Non-destructive testing of blueberry firmness by near-infrared diffuse reflectance[J]. Acta Agriculture Zhejiangensis,2015,27(9):1646−1651. doi: 10.3969/j.issn.1004-1524.2015.09.25 [13] 张丽娟, 夏其乐, 陈剑兵, 等. 近红外光谱的三种蓝莓果渣花色苷含量测定[J]. 光谱学与光谱分析,2020,40(7):2246−2252. [ZHANG Lijuan, XIA Qile, CHEN Jianbing, et al. Determination of anthocyanins in three kinds of blueberry pomace by near-infrared spectroscopy[J]. Spectroscopy and Spectral Analysis,2020,40(7):2246−2252. [14] ANDREAS K, FRANCESC X, PRENAFETA-BOLDU. Deep learning in agriculture: A survey[J]. Computers and Electronics in Agriculture,2018,147:70−90. doi: 10.1016/j.compag.2018.02.016
[15] 王璨, 武新慧, 李恋卿, 等. 卷积神经网络用于近红外光谱预测土壤含水率[J]. 光谱学与光谱分析,2018,38(1):36−41. [WANG Can, WU Xinhui, Li Lianqin, et al. Convolutional neural networks for predicting soil moisture content by near infrared spectroscopy[J]. Spectroscopy and Spectral Analysis,2018,38(1):36−41. [16] LIU J, ZHANG J X, TAN Z L, et al. Detecting the content of the bright blue pigment in cream based on deep learning and near-infrared spectroscopy[J]. Spectrochimica Acta Part A: Molecular and Biomolecular Spectroscopy,2022,270:120757. doi: 10.1016/j.saa.2021.120757
[17] DONG X, QUOCHUY V, BATUAN L. Salt content in saline-alkali soil detection using visible-near infrared spectroscopy and a 2D deep learning[J]. Microchemical Journal,2021,165:106182. doi: 10.1016/j.microc.2021.106182
[18] 孙志兴, 赵忠盖, 刘飞. 堆叠监督自动编码器的近红外光谱建模[J]. 光谱学与光谱分析,2022,42(3):749−756. [SUN Zhixing, ZHAO Zhonggai, LIU Fei. Near-infrared spectral modeling of stacked supervised autoencoders[J]. Spectroscopy and Spectral Analysis,2022,42(3):749−756. doi: 10.3964/j.issn.1000-0593(2022)03-0749-08 [19] LI L, ANDREW P, MARTHA W. Supervised autoencoders: Improving generalization performance with unsupervised regularizers[C]// Proceedings of the 32nd International Conference on Neural Information Processing Systems (NIPS'18), Red Hook, NY, USA: Curran Associates Inc. 2018: 107–117.
[20] 赵尔丰, 高畅, 高欣, 等. 酶-超声波辅助提取蓝莓果渣中花青素的工艺研究[J]. 东北农业大学学报,2010,41(4):98−103. [ZHAO Erfeng, GAO Chang, GAO Xin, et al. Study on the technology of enzyme-ultrasonic-assisted extraction of anthocyanins from blueberry pomace[J]. Journal of Northeast Agricultural University,2010,41(4):98−103. doi: 10.3969/j.issn.1005-9369.2010.04.021 [21] 刘仁道, 张猛, 李新贤. 草莓和蓝莓果实花青素提取及定量方法的比较[J]. 园艺学报,2008(5):655−660. [LIU Rendao, ZHANG Meng, LI Xinxian. Comparison of extraction and quantitative methods of anthocyanins from strawberry and blueberry fruits[J]. Acta Horticulturae Sinica,2008(5):655−660. doi: 10.16420/j.issn.0513-353x.2008.05.013 [22] 第五鹏瑶, 卞希慧, 王姿方, 等. 光谱预处理方法选择研究[J]. 光谱学与光谱分析,2019,39(9):2800−2806. [DI Wupengyao, BIAN Xihui, WANG Zifang, et al. Study on the selection of spectral preprocessing method[J]. Spectroscopy and Spectral Analysis,2019,39(9):2800−2806. [23] 张建勇, 高冉, 胡骏, 等. 灰色关联度和Pearson相关系数的应用比较[J]. 赤峰学院学报(自然科学版),2014,30(21):1−2. [ZHANG Jianyong, GAO Ran, HU Jun, et al. Application comparison of grey correlation degree and Pearson correlation coefficient[J]. Journal of Chifeng University (Natural Science Edition),2014,30(21):1−2. doi: 10.3969/j.issn.1673-260X.2014.21.001 [24] 罗一甲, 祝赫, 李潇涵, 等. 赤霞珠酿酒葡萄总酚含量的近红外光谱定量分析[J]. 光谱学与光谱分析,2021,41(7):2036−2042. [LUO Yijia, ZHU He, LI Xiaohan, et al. Quantitative analysis of total phenolic content in Cabernet Sauvignon wine grapes by near-infrared spectroscopy[J]. Spectroscopy and Spectral Analysis,2021,41(7):2036−2042. [25] LIN C, CHEN X, JIAN L, et al. Determination of grain protein content by near-infrared spectrometry and multivariate calibration in barley[J]. Food Chemistry,2014,162:10−15. doi: 10.1016/j.foodchem.2014.04.056
-
期刊类型引用(5)
1. 高含,刘锐,姜铖,王飞飞. 超高效液相色谱—串联质谱法测定植物油中甲胺磷残留量的不确定度评定. 食品与机械. 2024(10): 62-67 .  百度学术
百度学术
2. 董孝元,周玉,余义,刘莎,汪明迪,孙莉,唐艳荣. LC-ESI-MS/MS测定白酒中氨基甲酸乙酯的方法研究. 酿酒科技. 2023(11): 105-111 . 百度学术
3. 聂叶,焦富,罗汝叶,李巧玉,牟明月. 酱香型白酒酒醅中乙醇测定方法的不确定度评定. 酿酒科技. 2022(08): 125-130 . 百度学术
4. 陈同强,梁锋,吴海智,向俊,宋阳,荆辉华,袁列江,李灿,李凯龙. 气相色谱-质谱法测定发酵乳中氨基甲酸乙酯含量. 乳业科学与技术. 2022(06): 18-21 . 百度学术
5. 李正刚,马彧,王丹彧,李本淳,赵艳. HPLC法测定制何首乌饮片中2, 3, 5, 4'-四羟基二苯乙烯-2-O-β-D-葡萄糖苷含量的不确定度评估. 中国医药导刊. 2021(07): 522-525 . 百度学术
其他类型引用(0)


 下载:
下载:













计量
- 文章访问数: 116
- HTML全文浏览量: 34
- PDF下载量: 10
- 被引次数: 5



